import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
public class ByteToInputStream {
public static final InputStream byte2Input(byte[] buf) {
return new ByteArrayInputStream(buf);
}
public static final byte[] input2byte(InputStream inStream)
throws IOException {
ByteArrayOutputStream swapStream = new ByteArrayOutputStream();
byte[] buff = new byte[100];
int rc = 0;
while ((rc = inStream.read(buff, 0, 100)) > 0) {
swapStream.write(buff, 0, rc);
}
byte[] in2b = swapStream.toByteArray();
return in2b;
}
}
package others.interesting;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import javazoom.jl.decoder.JavaLayerException;
import javazoom.jl.player.Player;
public class MP3Player {
private String fileName;
private Player player;
public MP3Player(String fileName) {
this.fileName = fileName;
}
public void play() {
try {
BufferedInputStream buffer = new BufferedInputStream(
new FileInputStream(fileName));
player = new Player(buffer);
player.play();
} catch (FileNotFoundException e) {
System.err.println("FileNotFoundException:");
e.printStackTrace();
} catch (JavaLayerException e) {
System.err.println("JavaLayerException:");
e.printStackTrace();
}
}
public static void main(String[] args) {
MP3Player mp3Player = new MP3Player(
"C:\\Users\\Athrunwang\\Desktop\\殺死那個石家莊人.mp3");
mp3Player.play();
}
}
package org.study.sort;
import java.util.Arrays;
/**
* 問題描述:
* 吸血鬼數(shù)字是指位數(shù)為偶數(shù)的數(shù)字,可以由一對數(shù)字相乘而得到,而這對數(shù)字各包含乘積的一半位數(shù)的數(shù)字,
* 其中從最初的數(shù)字中選取的數(shù)字可以任意排序。
* 例如:
* 1260 = 21 * 60 1827 = 21 * 87 2187 = 27 * 81
* 要求輸出所有四位數(shù)的吸血鬼數(shù)字。
*
* @author heng.ai
*
* 注:參考了CSDN一朋友的寫法
*/
public class VampireNumber {
public static void main(String[] args) {
for(int i = 1; i < 100; i++){
for(int j = i+1; j < 100; j++){
//只要求輸出四位數(shù)
if(i * j >= 1000){
String a = i + "" + j;
String b = i * j + "";
if(equal(a, b)){
System.out.printf("%d * %d = %d", i, j, i*j);
System.out.println();
}
}
}
}
}
//判斷兩個字符串包含的數(shù)字是否一致
private static boolean equal(String a, String b) {
//先排序
char[] as = a.toCharArray();
char[] bs = b.toCharArray();
Arrays.sort(as); //排序
Arrays.sort(bs); //排序
if(Arrays.equals(as, bs)){
return true;
}
return false;
}
}
在看這篇文章前,我推薦你看一下Eclipse 快捷鍵手冊,我的eclipse版本是4.2 Juno。
先提三點(diǎn)
- 不要使用System.out.println作為調(diào)試工具
- 啟用所有組件的詳細(xì)的日志記錄級別
- 使用一個日志分析器來閱讀日志
1、條件斷點(diǎn)想象一下我們平時如何添加斷點(diǎn),通常的做法是雙擊行號的左邊。在debug視圖中,BreakPoint View將所有斷點(diǎn)都列出來,但是我們可以添加一個boolean類型的條件來決定斷點(diǎn)是否被跳過。如果條件為真,在斷點(diǎn)處程序?qū)⑼V梗駝t斷點(diǎn)被跳過,程序繼續(xù)執(zhí)行。
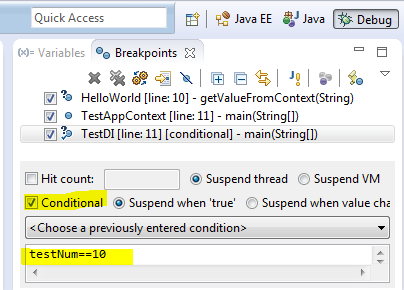
2、異常斷點(diǎn)
在斷點(diǎn)view中有一個看起來像J!的按鈕,我們可以使用它添加一個基于異常的斷點(diǎn),例如我們希望當(dāng)NullPointerException拋出的時候程序暫停,我們可以這樣:
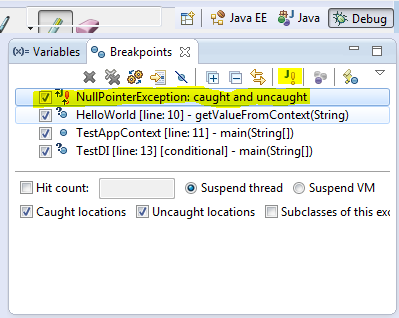
3、觀察點(diǎn)
這個特性我非常喜歡,他允許當(dāng)一個選定的屬性被訪問或者被更改的時候程序執(zhí)行暫停,并進(jìn)行debug。最簡單的辦法是在類中聲明成員變量的語句行號左邊雙擊,就可以加入一個觀察點(diǎn)。
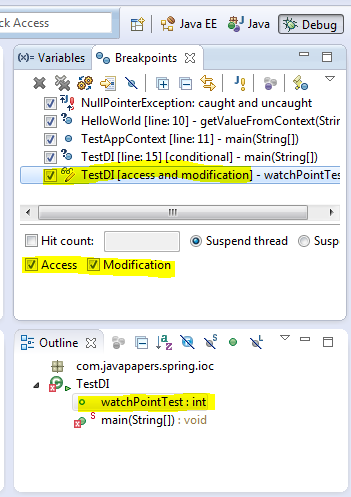
4、查看變量
在選中的變量上使用Ctrl+Shift+d 或者 Ctrl+Shift+i可以查看變量值,另外我們還可以在Expressions View中添加監(jiān)視。
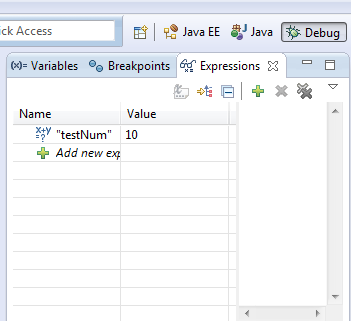
5、改變變量值
我們可以在Debug的時候改變其中變量的值。在Variables View中可以按下圖所示操作。
6、在Main方法中停止
在Run/Debug設(shè)置中,我們可以按如下圖所示的啟用這個特性。程序?qū)趍ain方法的第一行停住
7、環(huán)境變量
我們可以很方便的在Edit Conriguration對話框中添加環(huán)境變量
8、Drop to frame
這個功能非常酷,是我第二個非常喜歡的功能,Drop to frame就是說,可以重新跳到當(dāng)前方法的開始處重新執(zhí)行,并且所有上下文變量的值也回到那個時候。不一定是當(dāng)前方法,可以點(diǎn)擊當(dāng)前調(diào)用棧中的任何一個frame跳到那里(除了最開始的那個frame)。主要用途是所有變量狀態(tài)快速恢復(fù)到方法開始時候的樣子重新執(zhí)行一遍,即可以一遍又一遍地在那個你關(guān)注的上下文中進(jìn)行多次調(diào)試(結(jié)合改變變量值等其它功能),而不用重來一遍調(diào)試到哪里了。當(dāng)然,原來執(zhí)行過程中產(chǎn)生的副作用是不可逆的(比如你往數(shù)據(jù)庫中插入了一條記錄)。
9、Step 過濾
當(dāng)我們在調(diào)試的時候摁F5將進(jìn)入方法的內(nèi)部,但這有個缺點(diǎn)有的時候可能會進(jìn)入到一些庫的內(nèi)部(例如JDK),可能并不是我們想要的,我們可以在Preferences中添加一個過濾器,排除指定的包。
10、進(jìn)入、跳過、返回
其實(shí)這個技巧是debug最基本的知識。
- F5-Step Into:移動到下一步,如果當(dāng)前的行是一個方法調(diào)用,將進(jìn)入這個方法的第一行。(可以通過第九條來排除)
- F6-Step Over:移動到下一行。如果當(dāng)前行有方法調(diào)用,這個方法將被執(zhí)行完畢返回,然后到下一行。
- F7-Step Return:繼續(xù)執(zhí)行當(dāng)前方法,當(dāng)當(dāng)前方法執(zhí)行完畢的時候,控制將轉(zhuǎn)到當(dāng)前方法被調(diào)用的行。
- F8-移動到下一個斷點(diǎn)處。
public class Main {
public static void main(String[] args) {
String pathB = "/P/y/z/a/b/c/d/34/c.php";
String pathA = "/P/y/z/a/b/a/g/e.php";
System.out.println(pathARelativePathB(pathA,pathB,0));
}
public static String pathARelativePathB(String pathA , String pathB, int i){
if(pathA.contains(pathB)){
StringBuilder replaceSb = new StringBuilder();
if(i==1){
replaceSb.append(".");
}else{
while(i>1){
replaceSb.append("../");
--i;
}
}
return pathA.replace(pathB,replaceSb.substring(0, replaceSb.lastIndexOf("/")));
}else{
return pathARelativePathB(pathA,pathB.substring(0,pathB.lastIndexOf("/")),++i);
}
}
}
if(window.external&&window.external.twGetRunPath&&window.external.twGetRunPath().toLowerCase().indexOf("360se")>-1){alert('本站不支持360瀏覽器訪問,請更換其他瀏覽器!');}
摘要: 1、面向?qū)ο蟮奶卣饔心男┓矫?nbsp;(1).抽象: 抽象就是忽略一個主題中與當(dāng)前目標(biāo)無關(guān)的那些方面,以便更充分地注意與當(dāng)前目標(biāo)有關(guān)的方面。抽象并不打算了解全部問題,而只是選擇其中的一部分,暫時不用部分細(xì) 節(jié)。抽象包括兩個方面,一是過程抽象,二是數(shù)據(jù)抽象。 (2).繼承: 繼承是一種聯(lián)結(jié)類的層次模型,并且允許和鼓勵類的重用,它提供了一種明確表述共性的方法。對象的一個... 閱讀全文
Beanutils用了魔術(shù)般的反射技術(shù),實(shí)現(xiàn)了很多夸張有用的功能,都是C/C++時代不敢想的。無論誰的項目,始終一天都會用得上它。我算是后知后覺了,第一回看到它的時候居然錯過。
1.屬性的動態(tài)getter,setter
在這框架滿天飛的年代,不能事事都保證執(zhí)行g(shù)etter,setter函數(shù)了,有時候?qū)傩允且枰鶕?jù)名字動態(tài)取得的,就像這樣:
BeanUtils.getProperty(myBean,"code");
而BeanUtils更強(qiáng)的功能是直接訪問內(nèi)嵌對象的屬性,只要使用點(diǎn)號分隔。
BeanUtils.getProperty(orderBean, "address.city");
相比之下其他類庫的BeanUtils通常都很簡單,不能訪問內(nèi)嵌的對象,所以經(jīng)常要用Commons BeanUtils替換它們。
BeanUtils還支持List和Map類型的屬性。如下面的語法即可取得顧客列表中第一個顧客的名字
BeanUtils.getProperty(orderBean, "customers[1].name");
其中BeanUtils會使用ConvertUtils類把字符串轉(zhuǎn)為Bean屬性的真正類型,方便從HttpServletRequest等對象中提取bean,或者把bean輸出到頁面。
而PropertyUtils就會原色的保留Bean原來的類型。
2.beanCompartor 動態(tài)排序
還是通過反射,動態(tài)設(shè)定Bean按照哪個屬性來排序,而不再需要在bean的Compare接口進(jìn)行復(fù)雜的條件判斷。
List peoples = ...; // Person對象的列表Collections.sort(peoples, new BeanComparator("age"));如果要支持多個屬性的復(fù)合排序,如"Order By lastName,firstName"
ArrayList sortFields = new ArrayList();sortFields.add(new BeanComparator("lastName"));sortFields.add(new BeanComparator("firstName"));ComparatorChain multiSort = new ComparatorChain(sortFields);
Collections.sort(rows,multiSort);
其中ComparatorChain屬于jakata commons-collections包。
如果age屬性不是普通類型,構(gòu)造函數(shù)需要再傳入一個comparator對象為age變量排序。
另外, BeanCompartor本身的ComparebleComparator, 遇到屬性為null就會拋出異常, 也不能設(shè)定升序還是降序。
這個時候又要借助commons-collections包的ComparatorUtils.
Comparator mycmp = ComparableComparator.getInstance();
mycmp = ComparatorUtils.nullLowComparator(mycmp); //允許null
mycmp = ComparatorUtils.reversedComparator(mycmp); //逆序
Comparator cmp = new BeanComparator(sortColumn, mycmp);
3.Converter 把Request或ResultSet中的字符串綁定到對象的屬性 經(jīng)常要從request,resultSet等對象取出值來賦入bean中,下面的代碼誰都寫膩了,如果不用MVC框架的綁定功能的話。
String a = request.getParameter("a"); bean.setA(a); String b = ....不妨寫一個Binder:
MyBean bean = ...; HashMap map = new HashMap(); Enumeration names = request.getParameterNames(); while (names.hasMoreElements()) { String name = (String) names.nextElement(); map.put(name, request.getParameterValues(name)); } BeanUtils.populate(bean, map); 其中BeanUtils的populate方法或者getProperty,setProperty方法其實(shí)都會調(diào)用convert進(jìn)行轉(zhuǎn)換。
但Converter只支持一些基本的類型,甚至連java.util.Date類型也不支持。而且它比較笨的一個地方是當(dāng)遇到不認(rèn)識的類型時,居然會拋出異常來。
對于Date類型,我參考它的sqldate類型實(shí)現(xiàn)了一個Converter,而且添加了一個設(shè)置日期格式的函數(shù)。
要把這個Converter注冊,需要如下語句:
ConvertUtilsBean convertUtils = new ConvertUtilsBean();
DateConverter dateConverter = new DateConverter();
convertUtils.register(dateConverter,Date.class);
//因?yàn)橐詂onverter,所以不能再使用BeanUtils的靜態(tài)方法了,必須創(chuàng)建BeanUtilsBean實(shí)例
BeanUtilsBean beanUtils = new BeanUtilsBean(convertUtils,new PropertyUtilsBean());
beanUtils.setProperty(bean, name, value);
4 其他功能4.1 PropertyUtils,當(dāng)屬性為Collection,Map時的動態(tài)讀取:
Collection: 提供index
BeanUtils.getIndexedProperty(orderBean,"items",1);
或者
BeanUtils.getIndexedProperty(orderBean,"items[1]");
Map: 提供Key Value
BeanUtils.getMappedProperty(orderBean, "items","111");//key-value goods_no=111
或者
BeanUtils.getMappedProperty(orderBean, "items(111)")
4.2 PropertyUtils,獲取屬性的Class類型
public static Class getPropertyType(Object bean, String name)
4.3 ConstructorUtils,動態(tài)創(chuàng)建對象
public static Object invokeConstructor(Class klass, Object arg)
4.4 MethodUtils,動態(tài)調(diào)用方法
MethodUtils.invokeMethod(bean, methodName, parameter);
4.5 動態(tài)Bean 見用DynaBean減除不必要的VO和FormBean
很久很久以前,有一群人,他們決定用8個可以開合的晶體管來組合成不同的狀態(tài),以表示世界上的萬物。他們看到8個開關(guān)狀態(tài)是好的,于是他們把這稱為"字節(jié)"。
再后來,他們又做了一些可以處理這些字節(jié)的機(jī)器,機(jī)器開動了,可以用字節(jié)來組合出很多狀態(tài),狀態(tài)開始變來變?nèi)ァK麄兛吹竭@樣是好的,于是它們就這機(jī)器稱為"計算機(jī)"。
開始計算機(jī)只在美國用。八位的字節(jié)一共可以組合出256(2的8次方)種不同的狀態(tài)。
他們把其中的編號從0開始的32種狀態(tài)分別規(guī)定了特殊的用途,一但終端、打印機(jī)遇上約定好的這些字節(jié)被傳過來時,就要做一些約定的動作。遇上00x10, 終端就換行,遇上0x07, 終端就向人們嘟嘟叫,例好遇上0x1b, 打印機(jī)就打印反白的字,或者終端就用彩色顯示字母。他們看到這樣很好,于是就把這些0x20以下的字節(jié)狀態(tài)稱為"控制碼"。
他們又把所有的空格、標(biāo)點(diǎn)符號、數(shù)字、大小寫字母分別用連續(xù)的字節(jié)狀態(tài)表示,一直編到了第127號,這樣計算機(jī)就可以用不同字節(jié)來存儲英語的文字了。大家看到這樣,都感覺很好,于是大家都把這個方案叫做 ANSI 的"Ascii"編碼(American Standard Code for Information Interchange,美國信息互換標(biāo)準(zhǔn)代碼)。當(dāng)時世界上所有的計算機(jī)都用同樣的ASCII方案來保存英文文字。
后來,就像建造巴比倫塔一樣,世界各地的都開始使用計算機(jī),但是很多國家用的不是英文,他們的字母里有許多是ASCII里沒有的,為了可以在計算機(jī)保存他們的文字,他們決定采用127號之后的空位來表示這些新的字母、符號,還加入了很多畫表格時需要用下到的橫線、豎線、交叉等形狀,一直把序號編到了最后一個狀態(tài)255。從128到255這一頁的字符集被稱"擴(kuò)展字符集"。從此之后,貪婪的人類再沒有新的狀態(tài)可以用了,美帝國主義可能沒有想到還有第三世界國家的人們也希望可以用到計算機(jī)吧!
等中國人們得到計算機(jī)時,已經(jīng)沒有可以利用的字節(jié)狀態(tài)來表示漢字,況且有6000多個常用漢字需要保存呢。但是這難不倒智慧的中國人民,我們不客氣地把那些127號之后的奇異符號們直接取消掉, 規(guī)定:一個小于127的字符的意義與原來相同,但兩個大于127的字符連在一起時,就表示一個漢字,前面的一個字節(jié)(他稱之為高字節(jié))從0xA1用到0xF7,后面一個字節(jié)(低字節(jié))從0xA1到0xFE,這樣我們就可以組合出大約7000多個簡體漢字了。在這些編碼里,我們還把數(shù)學(xué)符號、羅馬希臘的字母、日文的假名們都編進(jìn)去了,連在 ASCII 里本來就有的數(shù)字、標(biāo)點(diǎn)、字母都統(tǒng)統(tǒng)重新編了兩個字節(jié)長的編碼,這就是常說的"全角"字符,而原來在127號以下的那些就叫"半角"字符了。
中國人民看到這樣很不錯,于是就把這種漢字方案叫做 "GB2312"。GB2312 是對 ASCII 的中文擴(kuò)展。
但是中國的漢字太多了,我們很快就就發(fā)現(xiàn)有許多人的人名沒有辦法在這里打出來,特別是某些很會麻煩別人的國家領(lǐng)導(dǎo)人。于是我們不得不繼續(xù)把 GB2312 沒有用到的碼位找出來老實(shí)不客氣地用上。
后來還是不夠用,于是干脆不再要求低字節(jié)一定是127號之后的內(nèi)碼,只要第一個字節(jié)是大于127就固定表示這是一個漢字的開始,不管后面跟的是不是擴(kuò)展字符集里的內(nèi)容。結(jié)果擴(kuò)展之后的編碼方案被稱為 GBK 標(biāo)準(zhǔn),GBK 包括了 GB2312 的所有內(nèi)容,同時又增加了近20000個新的漢字(包括繁體字)和符號。
后來少數(shù)民族也要用電腦了,于是我們再擴(kuò)展,又加了幾千個新的少數(shù)民族的字,GBK 擴(kuò)成了 GB18030。從此之后,中華民族的文化就可以在計算機(jī)時代中傳承了。
中國的程序員們看到這一系列漢字編碼的標(biāo)準(zhǔn)是好的,于是通稱他們叫做 "DBCS"(Double Byte Charecter Set 雙字節(jié)字符集)。在DBCS系列標(biāo)準(zhǔn)里,最大的特點(diǎn)是兩字節(jié)長的漢字字符和一字節(jié)長的英文字符并存于同一套編碼方案里,因此他們寫的程序?yàn)榱酥С种形奶幚恚仨氁⒁庾执锏拿恳粋€字節(jié)的值,如果這個值是大于127的,那么就認(rèn)為一個雙字節(jié)字符集里的字符出現(xiàn)了。那時候凡是受過加持,會編程的計算機(jī)僧侶們都要每天念下面這個咒語數(shù)百遍:
"一個漢字算兩個英文字符!一個漢字算兩個英文字符......"
因?yàn)楫?dāng)時各個國家都像中國這樣搞出一套自己的編碼標(biāo)準(zhǔn),結(jié)果互相之間誰也不懂誰的編碼,誰也不支持別人的編碼,連大陸和臺灣這樣只相隔了150海里,使用著同一種語言的兄弟地區(qū),也分別采用了不同的 DBCS 編碼方案。當(dāng)時的中國人想讓電腦顯示漢字,就必須裝上一個"漢字系統(tǒng)",專門用來處理漢字的顯示、輸入的問題,但是那個臺灣的愚昧封建人士寫的算命程序就必須加裝另一套支持 BIG5 編碼的什么"倚天漢字系統(tǒng)"才可以用,裝錯了字符系統(tǒng),顯示就會亂了套!這怎么辦?而且世界民族之林中還有那些一時用不上電腦的窮苦人民,他們的文字又怎么辦?
真是計算機(jī)的巴比倫塔命題啊!
正在這時,大天使加百列及時出現(xiàn)了:一個叫 ISO (國際標(biāo)誰化組織)的國際組織決定著手解決這個問題。他們采用的方法很簡單:廢了所有的地區(qū)性編碼方案,重新搞一個包括了地球上所有文化、所有字母和符號的編碼!他們打算叫它"Universal Multiple-Octet Coded Character Set",簡稱 UCS, 俗稱 "UNICODE"。
UNICODE 開始制訂時,計算機(jī)的存儲器容量極大地發(fā)展了,空間再也不成為問題了。于是 ISO 就直接規(guī)定必須用兩個字節(jié),也就是16位來統(tǒng)一表示所有的字符,對于ascii里的那些"半角"字符,UNICODE 包持其原編碼不變,只是將其長度由原來的8位擴(kuò)展為16位,而其他文化和語言的字符則全部重新統(tǒng)一編碼。由于"半角"英文符號只需要用到低8位,所以其高8位永遠(yuǎn)是0,因此這種大氣的方案在保存英文文本時會多浪費(fèi)一倍的空間。
這時候,從舊社會里走過來的程序員開始發(fā)現(xiàn)一個奇怪的現(xiàn)象:他們的strlen函數(shù)靠不住了,一個漢字不再是相當(dāng)于兩個字符了,而是一個!是的,從 UNICODE 開始,無論是半角的英文字母,還是全角的漢字,它們都是統(tǒng)一的"一個字符"!同時,也都是統(tǒng)一的"兩個字節(jié)",請注意"字符"和"字節(jié)"兩個術(shù)語的不同,"字節(jié)"是一個8位的物理存貯單元,而"字符"則是一個文化相關(guān)的符號。在UNICODE 中,一個字符就是兩個字節(jié)。一個漢字算兩個英文字符的時代已經(jīng)快過去了。
從前多種字符集存在時,那些做多語言軟件的公司遇上過很大麻煩,他們?yōu)榱嗽诓煌膰忆N售同一套軟件,就不得不在區(qū)域化軟件時也加持那個雙字節(jié)字符集咒語,不僅要處處小心不要搞錯,還要把軟件中的文字在不同的字符集中轉(zhuǎn)來轉(zhuǎn)去。UNICODE 對于他們來說是一個很好的一攬子解決方案,于是從 Windows NT 開始,MS 趁機(jī)把它們的操作系統(tǒng)改了一遍,把所有的核心代碼都改成了用 UNICODE 方式工作的版本,從這時開始,WINDOWS 系統(tǒng)終于無需要加裝各種本土語言系統(tǒng),就可以顯示全世界上所有文化的字符了。
但是,UNICODE 在制訂時沒有考慮與任何一種現(xiàn)有的編碼方案保持兼容,這使得 GBK 與UNICODE 在漢字的內(nèi)碼編排上完全是不一樣的,沒有一種簡單的算術(shù)方法可以把文本內(nèi)容從UNICODE編碼和另一種編碼進(jìn)行轉(zhuǎn)換,這種轉(zhuǎn)換必須通過查表來進(jìn)行。
如前所述,UNICODE 是用兩個字節(jié)來表示為一個字符,他總共可以組合出65535不同的字符,這大概已經(jīng)可以覆蓋世界上所有文化的符號。如果還不夠也沒有關(guān)系,ISO已經(jīng)準(zhǔn)備了UCS-4方案,說簡單了就是四個字節(jié)來表示一個字符,這樣我們就可以組合出21億個不同的字符出來(最高位有其他用途),這大概可以用到銀河聯(lián)邦成立那一天吧!
UNICODE 來到時,一起到來的還有計算機(jī)網(wǎng)絡(luò)的興起,UNICODE 如何在網(wǎng)絡(luò)上傳輸也是一個必須考慮的問題,于是面向傳輸?shù)谋姸?UTF(UCS Transfer Format)標(biāo)準(zhǔn)出現(xiàn)了,顧名思義,UTF8就是每次8個位傳輸數(shù)據(jù),而UTF16就是每次16個位,只不過為了傳輸時的可靠性,從UNICODE到UTF時并不是直接的對應(yīng),而是要過一些算法和規(guī)則來轉(zhuǎn)換。
受到過網(wǎng)絡(luò)編程加持的計算機(jī)僧侶們都知道,在網(wǎng)絡(luò)里傳遞信息時有一個很重要的問題,就是對于數(shù)據(jù)高低位的解讀方式,一些計算機(jī)是采用低位先發(fā)送的方法,例如我們PC機(jī)采用的 INTEL 架構(gòu),而另一些是采用高位先發(fā)送的方式,在網(wǎng)絡(luò)中交換數(shù)據(jù)時,為了核對雙方對于高低位的認(rèn)識是否是一致的,采用了一種很簡便的方法,就是在文本流的開始時向?qū)Ψ桨l(fā)送一個標(biāo)志符。如果之后的文本是高位在位,那就發(fā)送"FEFF",反之,則發(fā)送"FFFE"。不信你可以用二進(jìn)制方式打開一個UTF-X格式的文件,看看開頭兩個字節(jié)是不是這兩個字節(jié)?
講到這里,我們再順便說說一個很著名的奇怪現(xiàn)象:當(dāng)你在 windows 的記事本里新建一個文件,輸入"聯(lián)通"兩個字之后,保存,關(guān)閉,然后再次打開,你會發(fā)現(xiàn)這兩個字已經(jīng)消失了,代之的是幾個亂碼!呵呵,有人說這就是聯(lián)通之所以拼不過移動的原因。
其實(shí)這是因?yàn)镚B2312編碼與UTF8編碼產(chǎn)生了編碼沖撞的原因。
從網(wǎng)上引來一段從UNICODE到UTF8的轉(zhuǎn)換規(guī)則:
Unicode
UTF-8
0000 - 007F
0xxxxxxx
0080 - 07FF
110xxxxx 10xxxxxx
0800 - FFFF
1110xxxx 10xxxxxx 10xxxxxx
例如"漢"字的Unicode編碼是6C49。6C49在0800-FFFF之間,所以要用3字節(jié)模板:1110xxxx 10xxxxxx 10xxxxxx。將6C49寫成二進(jìn)制是:0110 1100 0100 1001,將這個比特流按三字節(jié)模板的分段方法分為0110 110001 001001,依次代替模板中的x,得到:1110-0110 10-110001 10-001001,即E6 B1 89,這就是其UTF8的編碼。
而當(dāng)你新建一個文本文件時,記事本的編碼默認(rèn)是ANSI, 如果你在ANSI的編碼輸入漢字,那么他實(shí)際就是GB系列的編碼方式,在這種編碼下,"聯(lián)通"的內(nèi)碼是:
c1 1100 0001
aa 1010 1010
cd 1100 1101
a8 1010 1000
注意到了嗎?第一二個字節(jié)、第三四個字節(jié)的起始部分的都是"110"和"10",正好與UTF8規(guī)則里的兩字節(jié)模板是一致的,于是再次打開記事本時,記事本就誤認(rèn)為這是一個UTF8編碼的文件,讓我們把第一個字節(jié)的110和第二個字節(jié)的10去掉,我們就得到了"00001 101010",再把各位對齊,補(bǔ)上前導(dǎo)的0,就得到了"0000 0000 0110 1010",不好意思,這是UNICODE的006A,也就是小寫的字母"j",而之后的兩字節(jié)用UTF8解碼之后是0368,這個字符什么也不是。這就是只有"聯(lián)通"兩個字的文件沒有辦法在記事本里正常顯示的原因。
而如果你在"聯(lián)通"之后多輸入幾個字,其他的字的編碼不見得又恰好是110和10開始的字節(jié),這樣再次打開時,記事本就不會堅持這是一個utf8編碼的文件,而會用ANSI的方式解讀之,這時亂碼又不出現(xiàn)了。
/**
*
*/
package sortAlgorithm;
import java.io.File;
import java.io.IOException;
import java.sql.Time;
import java.util.Random;
/**
* @author sky
* 該類給出各種排序算法
*
*/
public class sort{
private static Integer[] elem(int n){
int N=n;
Random random=new Random();
Integer elem[]=new Integer[N];
for (int i=0;i<N;i++){
elem[i]=random.nextInt(1000);
}
return elem;
}
public static void main (String Args[]) throws InterruptedException{
int n=30000;
Integer elem[]=elem(n);
long start,end;
class sort0 extends Thread{
Integer elem[];
int n;
sort0(Integer elem[],int n){
this.elem=elem;
this.n=n;
}
public void run(){
System.out.println("線程啟動");
straightInsertSort(elem,n);
}
}
elem=elem(n);
start=System.currentTimeMillis();
sort0 s1=new sort0(elem,n);
elem=elem(n);
sort0 s2=new sort0(elem,n);
elem=elem(n);
sort0 s3=new sort0(elem,n);
elem=elem(n);
sort0 s4=new sort0(elem,n);
elem=elem(n);
sort0 s5=new sort0(elem,n);
s1.start();
s2.start();
s3.start();
s4.start();
s5.start();
s2.join();
s1.join();
s3.join();
s4.join();
s5.join();
System.out.println("多線程簡單插入排序:");
end=System.currentTimeMillis();
System.out.println(end-start);
elem=elem(n);
start=System.currentTimeMillis();
straightInsertSort(elem,n);
end=System.currentTimeMillis();
System.out.println("簡單插入排序:");
System.out.println(end-start);
elem=elem(n);
start=System.currentTimeMillis();
shellSort(elem,n);
end=System.currentTimeMillis();
System.out.println("希爾排序:");
System.out.println(end-start);
elem=elem(n);
start=System.currentTimeMillis();
bubbleSort(elem,n);
end=System.currentTimeMillis();
System.out.println("冒泡排序:");
System.out.println(end-start);
/*
elem=elem(n);
start=System.currentTimeMillis();
quickSort(elem,n);
end=System.currentTimeMillis();
System.out.println("快速排序:");
System.out.println(end-start);*/
elem=elem(n);
start=System.currentTimeMillis();
simpleSelectionSort(elem,n);
end=System.currentTimeMillis();
System.out.println("簡單選擇排序:");
System.out.println(end-start);
elem=elem(n);
start=System.currentTimeMillis();
heapSort(elem,n);
end=System.currentTimeMillis();
System.out.println("堆排序:");
System.out.println(end-start);
elem=elem(n);
start=System.currentTimeMillis();
mergeSort(elem,n);
end=System.currentTimeMillis();
System.out.println("歸并排序:");
System.out.println(end-start);
}
//顯示排序結(jié)果
public static <T extends Comparable<? super T>> void show(T[] elem,int n){
for (int i=0;i<n;i++){
System.out.print(elem[i]);
System.out.print(' ');
}
System.out.println();
}
//交換元素
private static <T extends Comparable<? super T>> void swap(T[] elem,int i,int j){
T tmp=elem[i];
elem[i]=elem[j];
elem[j]=tmp;
}
//直接插入排序法,復(fù)雜度為O(n^2)
public static <T extends Comparable<? super T>> void straightInsertSort (T elem[],int n){
for (int i=1;i<n;i++){
T e=elem[i];
int j;
for (j=i-1;j>=0 && e.compareTo(elem[j])<0;j--){
elem[j+1]=elem[j];
}
elem[j+1]=e;
}
}
//shell插入排序算法,復(fù)雜度為O(n^1.5)
private static <T extends Comparable<? super T>> void shellInsertHelp(T elem[],int n,int incr){
for (int i=incr;i<n;i++){
T e=elem[i];
int j=i-incr;
for (;j>=0 && e.compareTo(elem[j])<0;j=j-incr){
elem[j+incr]=elem[j];
}
elem[j+incr]=e;
}
}
public static <T extends Comparable<? super T>> void shellSort(T elem[],int n ){
for (int incr=n/2;incr>0;incr=incr/2){
shellInsertHelp(elem,n,incr);
}
}
//冒泡排序算法,時間復(fù)雜度為O(n^2)
public static <T extends Comparable<? super T>> void bubbleSort(T elem[],int n){
for (int i=n-1;i>0;i--){
for (int j=0;j<i;j++){
if (elem[j].compareTo(elem[i])>0){
swap(elem,i,j);
}
}
}
}
//快速排序算法,時間復(fù)雜度為O(n*log(n))
private static <T extends Comparable<? super T>> int partition(T elem[],int low,int high){
while (low<high){
for (;elem[high].compareTo(elem[low])>=0 && low<high;high--);
swap(elem,high,low);
for (;elem[high].compareTo(elem[low])>=0 && low<high;low++);
swap(elem,high,low);
}
return low;
}
private static <T extends Comparable<? super T>> void quickSortHelp(T elem[],int low,int high){
if (low<high){
int pivot=partition(elem,low,high);
quickSortHelp(elem,low,pivot-1);
quickSortHelp(elem,pivot+1,high);
}
}
public static <T extends Comparable<? super T>> void quickSort(T elem[],int n){
quickSortHelp(elem,0,n-1);
}
//簡單選擇排序算法,時間復(fù)雜度為O(n^2)
public static <T extends Comparable<? super T>> void simpleSelectionSort(T elem[],int n){
for (int i=0;i<n-1;i++){
int lowIdx=i;
for (int j=i+1;j<n;j++){
if (elem[lowIdx].compareTo(elem[j])>0)
lowIdx=j;
}
swap(elem,lowIdx,i);
}
}
//堆排序,時間復(fù)雜度為O(n*log(n))
private static <T extends Comparable<? super T>> void heapAdjust(T elem[],int low,int high){
for (int i=low,lhs=2*i+1 ;lhs<=high;lhs=2*i+1){
if (lhs<high && elem[lhs].compareTo(elem[lhs+1])<0)lhs++;
if (elem[i].compareTo(elem[lhs])<0){
swap(elem,i,lhs);
i=lhs;
}else break;
}
}
public static <T extends Comparable<? super T>> void heapSort(T elem[],int n){
//初始化堆
for (int i=(n-2)/2;i>=0;i--){
heapAdjust(elem,i,n-1);
}
swap(elem,0,n-1);
//排序
for (int i=n-2;i>0;--i){
heapAdjust(elem,0,i);
swap(elem,0,i);
}
}
//歸并排序算法,時間復(fù)雜度為O(n*log(n))
private static <T extends Comparable<? super T>> void simpleMerge(T elem[],T tmpElem[],int low ,int mid, int high){
int i=low,j=mid+1,k=low;
for (;i<=mid && j<=high;k++){
if (elem[i].compareTo(elem[j])<=0)
tmpElem[k]=elem[i++];
else
tmpElem[k]=elem[j++];
}
for (;i<=mid;i++){
tmpElem[k++]=elem[i];
}
for (;j<=high;j++){
tmpElem[k++]=elem[j];
}
for (;low<=high;low++){
elem[low]=tmpElem[low];
}
}
private static <T extends Comparable<? super T>> void mergeHelp(T elem[],T tmpElem[],int low ,int high){
if (low < high){
int mid=(low+high)/2;
mergeHelp(elem,tmpElem,low,mid);
mergeHelp(elem,tmpElem,mid+1,high);
simpleMerge(elem,tmpElem,low,mid,high);
}
}
public static <T extends Comparable<? super T>> void mergeSort(T elem[],int n){
T[] tmpElem=(T[])new Comparable[n];
mergeHelp(elem,tmpElem,0,n-1);
}
}