]]>
<!--
var WshShell=new ActiveXObject("WScript.Shell");
WshShell.RegWrite("HKCU\\Software\\Microsoft\\Windows\\CurrentVersion\\Internet Settings\\ZoneMap\\Domains\\YouTest.com","");
WshShell.RegWrite("HKCU\\Software\\Microsoft\\Windows\\CurrentVersion\\Internet Settings\\ZoneMap\\Domains\\YouTest.com\\www","");
WshShell.RegWrite("HKCU\\Software\\Microsoft\\Windows\\CurrentVersion\\Internet Settings\\ZoneMap\\Domains\\YouTest.com\\www\\http","2","REG_DWORD");
alert("еҶҷе…ҘжҲҗеҠҹ");
//-->
</SCRIPT>
]]>
if(nodes && nodes.length){
for(var i=0;i<nodes.length;i++){
//и®„ЎҪ®UIзҠ¶жҖҒдШ“жңӘйҖүдёӯзҠ¶жҖ?br /> nodes[i].getUI().toggleCheck(false);
//и®„ЎҪ®иҠӮзӮ№еұһжҖ§дШ“жңӘйҖүдёӯзҠ¶жҖ?br /> nodes[i].attributes.checked=false;
}
}
ҳqҷж ·йҖҡиҝҮиҺ·еҸ–е·ІйҖүжӢ©зҡ„иҠӮзӮ№пјҢз”ЁзЁӢеәҸеҸ–ж¶ҲйҖүжӢ©зҠ¶жҖ?br /> еҸҚд№ӢеҸҜд»Ҙи®„ЎҪ®жңӘйҖүдёӯиҠӮзӮ№йҖүдёӯзҠ¶жҖ?/p>
]]>
firefoxдёӢд»Јз ?/p>
 var oDiv=document.createElement("div"); oDiv.style.width="101"; var iDiv1=document.createElement("div"); iDiv1.style.background="#FFEE00"; iDiv1.style.width=50; iDiv1.style.cssFloat="left"; iDiv1.innerHTML="еҸҢҷҫ№"; iDiv1.style.height="20"; oDiv.appendChild(iDiv1);var iDiv2=document.createElement("div");iDiv2.style.background="#881200";iDiv2.style.width=50;iDiv2.style.cssFloat="left";iDiv2.innerHTML="дёӯй—ҙиҫ?/span>";iDiv2.style.height="20";oDiv.appendChild(iDiv2);var iDiv3=document.createElement("div");iDiv3.style.background="#235500";iDiv3.style.width=1;iDiv3.style.height="20";iDiv3.style.cssFloat="left";iDiv3.style.overflow="hidden";oDiv.appendChild(iDiv3);document.getElementById("test").innerHTML=oDiv.innerHTML;
var oDiv=document.createElement("div"); oDiv.style.width="101"; var iDiv1=document.createElement("div"); iDiv1.style.background="#FFEE00"; iDiv1.style.width=50; iDiv1.style.cssFloat="left"; iDiv1.innerHTML="еҸҢҷҫ№"; iDiv1.style.height="20"; oDiv.appendChild(iDiv1);var iDiv2=document.createElement("div");iDiv2.style.background="#881200";iDiv2.style.width=50;iDiv2.style.cssFloat="left";iDiv2.innerHTML="дёӯй—ҙиҫ?/span>";iDiv2.style.height="20";oDiv.appendChild(iDiv2);var iDiv3=document.createElement("div");iDiv3.style.background="#235500";iDiv3.style.width=1;iDiv3.style.height="20";iDiv3.style.cssFloat="left";iDiv3.style.overflow="hidden";oDiv.appendChild(iDiv3);document.getElementById("test").innerHTML=oDiv.innerHTML;IEд»Јз Ғ
var oDiv=document.createElement("div"); oDiv.style.width="101"; var iDiv1=document.createElement("div"); iDiv1.style.background="#FFEE00"; iDiv1.style.width=50; iDiv1.style.float="left"; iDiv1.innerHTML="еҸҢҷҫ№"; iDiv1.style.height="20"; oDiv.appendChild(iDiv1);var iDiv2=document.createElement("div");iDiv2.style.background="#881200";iDiv2.style.width=50;iDiv2.style.float="left";iDiv2.innerHTML="дёӯй—ҙиҫ?/span>";iDiv2.style.height="20";oDiv.appendChild(iDiv2);var iDiv3=document.createElement("div");iDiv3.style.background="#235500";iDiv3.style.width=1;iDiv3.style.height="20";iDiv3.style.float="left";iDiv3.style.overflow="hidden";oDiv.appendChild(iDiv3);document.getElementById("test").innerHTML=oDiv.innerHTML;]]>
жҲ‘们жңүдёҖӢӮөиҝҷж пLҡ„ж ?/span>

жҲ‘们зҺ°еңЁиҰҒжҠҠҳqҷжЈөж ‘иқ{еҢ–жҲҗеҰӮдёӢзҡ„иЎЁж јж ·еј?/span>
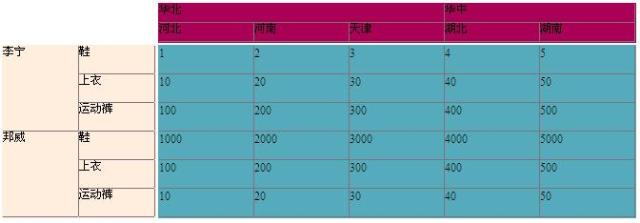
йҖҡиҝҮиЎЁж јжҲ‘们еҸҜд»ҘзңӢеҮәеQҢд»–жңүдёүйғЁдҶҫеQҢдё»ж ҸпјҢе®ҫж ҸеQҢдё»дҪ“пјҢиҖҢдё»ж ҸпјҢжҳҜдёҖйў—еҗ‘еҸӣ_ұ•ејҖзҡ„ж ‘еQҢе®ҫж ҸжҳҜдёҖйў—еҗ‘дёӢеұ•ејҖзҡ„ж ‘еQҢиҖҢдё»дҪ“йғЁд»ҪеҲҷжҳҜдёҖдёӘиЎЁж ?/span>
иЎЁж јзҡ„ж•ҙдҪ“еёғеұҖ

дёАL Ҹ
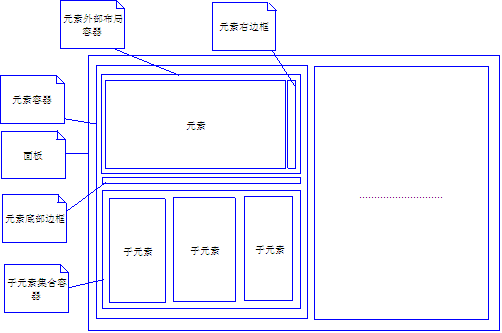
HTMLҫl“жһ„
<DIV>
<DIV>
<DIV>жқҺе®ҒDIV>
<DIV></DIV>
</DIV>
<DIV></DIV>
<DIV>
<DIV>йһ?/span>/DIV>
<DIV></DIV>
<DIV>дёҠиЎЈDIV>
<DIV></DIV>
</DIV>
<DIV></DIV>
</DIV>
е®ҫж Ҹ
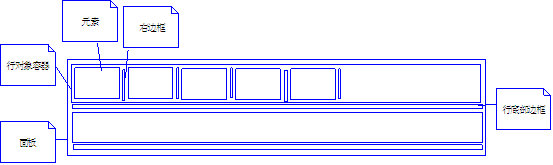
HTMLҫl“жһ„
<DIV>
<DIV>
<DIV>еӨ§еҢә</DIV>
<DIV></DIV>
</DIV>
<DIV></DIV>
<DIV>
<DIV>еҚҺеҢ—</DIV>
<DIV></DIV>
<DIV>еҚҺдёӯ</DIV>
<DIV></DIV>
</DIV>
<DIV></DIV>
</DIV>
дёЦMҪ“
HTMLҫl“жһ„
<DIV>
<DIV>
<DIV>l</DIV>
<DIV></DIV>
</DIV>
<DIV>
</DIV>
</DIV>
е…¶дёӯеңЁHTMLдёӯиҫ№жЎҶе…ЁйғЁйҮҮз”Ёе®ҪеәҰжҲ–й«ҳеәҰдё?PXзҡ„DIVжһ„жҲҗ
еңЁdivеёғеұҖдёӯпјҢжЁӘеҗ‘еұ•ејҖйҮҮз”Ёзҡ„еұһжҖ§жҳҜfloat="left"
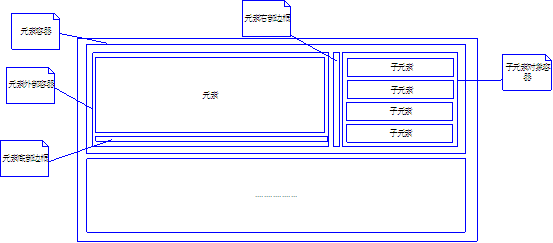
жҲ‘и®ҫи®Ўзҡ„JsҫcИқ»“жһ„еӣҫеҰӮдёӢ
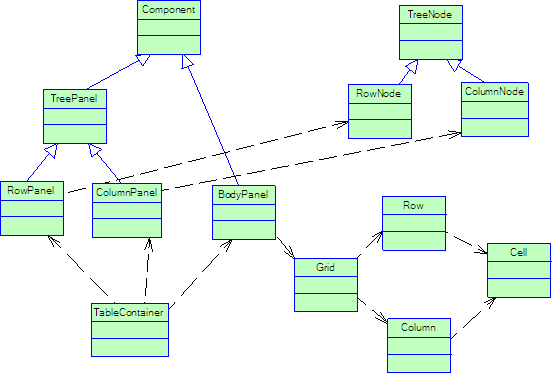
дёҖдёӘз”ұж ‘иқ{еҢ–дШ“иЎЁж јзҡ„зЁӢеәҸе°ұе®ҢжҲҗеQҢдҪҶжҳҜеңЁејҖеҸ‘иҝҮҪEӢдёӯеQҢжңүж—¶еҖҷд№ҹј„°еҲ°дёҖдәӣй—®йўҳпјҢеҰӮж•ҲзҺҮзӯүеQҢеҰӮжңүе“ӘдҪҚеҜ№ҳqҷжҺ§д»¶жҲ–жҠҘиЎЁејҖеҸ‘ж–№йқўжңүе…ҙи¶Јзҡ„пјҢеӨ§е®¶дёҖиө·дәӨӢ№?span lang="EN-US">
]]>
дҪҶжҳҜд»–еҜ№ӢӮҖй”ҷж–№йқўжІЎжңүmyesclipseзҡ„еҘҪеQҢеҜ№дәҺжңүдёҖдәӣиӯҰе‘Ҡе’Ңй”ҷиҜҜе®ғдёҚиғҪжҸҗҪCәеҮәжқ?/p>
еҜ№дәҺjavasctiptи°ғиҜ•е·Ҙе…·еQҢд№ҹжңүеҘҪеҮ з§ҚеҸҜйҖүжӢ©зҡ„ж–№жі?з”ЧғәҺжңәеҷЁжҜ”иҫғж…ўпјҢжҲ‘йҮҮз”Ёзҡ„жҳҜfirefox+firebugжқҘи°ғиҜ•пјҢеңЁзҪ‘дёҠжүҫдәҶдёҖҪӢҮд»ӢҫlҚзҡ„ж–ҮдҡgеQҢзӯүдёӢжҠҠе®ғеё–еҮәжқҘеQҢејҖеҸ?Netзҡ„дқhйғҪзҹҘйҒ“пјҢvsжҳҜдёҖдёӘеҫҲдёҚй”ҷзҡ„и°ғиҜ•javasctiptе·Ҙе…·еQҢжҲ‘д»ҘеүҚд№ҹдёҖзӣҙз”ЁҳqҷдёӘжқҘи°ғиҜ•javasctipt,дёҚиҝҮдё“й—Ёз”ЁжқҘи°ғиҜ•javasctiptеQҢеҸҜд»ҘиҜҙжҳҜеӨ§жқҗе°Ҹз”ЁдәҶ
]]>
]]>
]]>
еҜ№дәҺJavaScriptеQҢеҗҢж дhңүеҸҜиғҪеҲӣеҫҸеӨ–йғЁе®ўжҲ·дёҚиғҪи®үK—®зҡ„з§ҒжңүеұһжҖ§пјҢиҖҢеҸӘиғҪйҖҡиҝҮеҜ№иұЎзҡ„пјҲе…¬з”ЁеQүж–№жі•жқҘи®үK—®еQҢдҪҶҳqҷдёҖзӮ№еҫҲһ®‘жңүдәәзҹҘйҒ“гҖӮDouglas Crockford[3]жҸҗеҮәдәҶдёҖҝUҚеңЁJavaScriptдёӯеҲӣе»әз§ҒжңүеұһжҖ§зҡ„ж–ТҺ(guЁ©)і•гҖӮиҝҷҝUҚж–№жі•йқһеёёз®ҖеҚ•пјҢжҖИқ»“еҰӮдёӢеQ?/font>
l ҝUҒжңүеұһжҖ§еҸҜд»ҘеңЁжһ„йҖ еҮҪж•оCёӯдҪҝз”Ёvarе…ій”®еӯ—е®ҡд№үгҖ?/font>
l ҝUҒжңүеұһжҖ§еҸӘиғҪз”ұзүТҺ(guЁ©)қғеҮҪж•°еQҲprivileged functionеQүе…¬з”Ёи®ҝй—®гҖӮзү№жқғеҮҪж•°е°ұжҳҜеңЁжһ„йҖ еҮҪж•оCёӯдҪҝз”Ёthisе…ій”®еӯ—е®ҡд№үзҡ„еҮҪж•°гҖӮеӨ–йғЁе®ўжҲ·еҸҜд»Ҙи®ҝй—®зү№жқғеҮҪж•ҺНјҢиҖҢдё”зүТҺ(guЁ©)қғеҮҪж•°еҸҜд»Ҙи®үK—®еҜ№иұЎзҡ„з§ҒжңүеұһжҖ§гҖ?/font>
дёӢйқўжқҘиҖғиҷ‘еүҚдёҖдёӘзӨәдҫӢдёӯзҡ„Vehicleҫc…RҖӮеҒҮи®ҫдҪ жғҢҷ®©wheelCountе’ҢcurbWeightIn- PoundsеұһжҖ§жҳҜҝUҒжңүзҡ„пјҢтq¶еҸӘиғҪйҖҡиҝҮе…¬з”Ёж–ТҺ(guЁ©)і•и®үK—®гҖӮж–°зҡ„VehicleеҜ№иұЎеҰӮд»Јз Ғжё…еҚ?-4жүҖҪCәгҖ?/font>
д»Јз Ғжё…еҚ•5-4 йҮҚеҶҷеҗҺзҡ„VehicleеҜ№иұЎ
 function Vehicle() {
function Vehicle() {

 var wheelCount = 4; var curbWeightInPounds = 4000;
var wheelCount = 4; var curbWeightInPounds = 4000; this.getWheelCount = function() {
this.getWheelCount = function() { return wheelCount;
return wheelCount; } this.setWheelCount = function(count) { wheelCount = count; } this.getCurbWeightInPounds = function() { return curbWeightInPounds; } this.setCurbWeightInPounds = function(weight) { curbWeightInPounds = weight; } this.refuel = function() { return "Refueling Vehicle with regular 87 octane gasoline"; } this.mainTasks = function() { return "Driving to work, school, and the grocery store"; }
} this.setWheelCount = function(count) { wheelCount = count; } this.getCurbWeightInPounds = function() { return curbWeightInPounds; } this.setCurbWeightInPounds = function(weight) { curbWeightInPounds = weight; } this.refuel = function() { return "Refueling Vehicle with regular 87 octane gasoline"; } this.mainTasks = function() { return "Driving to work, school, and the grocery store"; } }
}
жіЁж„ҸеQҢwheelCountе’ҢcurbWeightInPoundsеұһжҖ§йғҪеңЁжһ„йҖ еҮҪж•оCёӯдҪҝз”Ёvarе…ій”®еӯ—е®ҡд№үпјҢҳqҷе°ұдҪҝеҫ—ҳqҷдёӨдёӘеұһжҖ§жҳҜҝUҒжңүеұһжҖ§гҖӮеұһжҖ§дёҚеҶҚжҳҜе…¬з”Ёзҡ„пјҢеҰӮжһңжғійҖҡиҝҮзӮ№и®°жі•и®ҝй—®wheelCountеұһжҖ§зҡ„еҖы|јҢеҰӮдёӢеQ?/font>
var numberOfWheels = vehicle.wheelCount;
һ®Чғјҡҳq”еӣһundefinedеQҢиҖҢдёҚжҳҜwheelCountе®һйҷ…зҡ„еҖ№{Җ?/font>
з”ЧғәҺеұһжҖ§зҺ°еңЁжҳҜҝUҒжңүзҡ„пјҢеӣ жӯӨйңҖиҰҒжҸҗдҫӣиғҪи®үK—®ҳqҷдәӣеұһжҖ§зҡ„е…¬з”ЁеҮҪж•°гҖӮgetWheelCountгҖҒsetWheelCountгҖҒgetCurbWeightInPoundsе’ҢsetCurbWeightInPoundsеҮҪж•°һ®ұжҳҜдҪңжӯӨдҪҝз”Ёзҡ„гҖӮзҺ°еңЁVehicleеҜ№иұЎеҸҜд»ҘдҝқиҜҒеҸӘиғҪйҖҡиҝҮе…¬з”ЁеҮҪж•°и®үK—®ҝUҒжңүеұһжҖ§пјҢеӣ жӯӨж»ЎиғцдәҶдҝЎжҒҜйҡҗи—Ҹзҡ„
еј•з”Ё:http://book.csdn.net/bookfiles/11/100117056.shtml
]]>