近期項目需要,做了一段時間的SQL Server性能優化�,遇到了一些問題��,也積累了一些經驗,現總結一下��,與君共享��。SQL Server性能優化涉及到許多方面��,如良好的系統和數據庫設計,優質的SQL編寫����,合適的數據表索引設計�,甚至各種硬件因素:網絡性能��、服務器的性能、操作系統的性能,甚至網卡、交換機等���。這篇文章主要講到如何改善索引,還將有另一篇討論如何改善SQL語句。
首先需要強調一下�,水能載舟��,亦能覆舟。建立“適當”的索引是實現查詢優化的首要前提�。
當根據索引碼的值搜索數據時���,索引提供了對數據的快速訪問����。事實上�����,沒有索引,數據庫也能根據SELECT語句成功地檢索到結果�����,但隨著表變得越來越大,使用“適當”的索引的效果就越來越明顯。索引有助于提高檢索性能�,但過多或不當的索引也會導致系統低效�。因為用戶在表中每加進一個索引��,數據庫就要做更多的工作���。過多的索引甚至會導致索引碎片�����。所以,要建立一個“適當”的索引體系����,特別是對聚合索引的創建,更應精益求精����,以使數據庫能得到高性能的發揮�。
簡述SQL Server的索引
SQL Server提供了兩種索引:聚集索引(clustered index�,也稱聚類索引、簇集索引)和非聚集索引(nonclustered index�,也稱非聚類索引����、非簇集索引)��。
聚集索引確定表中數據的物理順序�����。聚集索引類似于電話簿,后者按姓氏排列數據���。由于聚集索引規定數據在表中的物理存儲順序,因此一個表只能包含一個聚集索引���。但該索引可以包含多個列(組合索引),就像電話簿按姓氏和名字進行組織一樣����。
聚集索引對于那些經常要搜索范圍值的列特別有效�����。使用聚集索引找到包含第一個值的行后��,便可以確保包含后續索引值的行在物理相鄰。例如����,如果應用程序執行的一個查詢經常檢索某一日期范圍內的記錄�����,則使用聚集索引可以迅速找到包含開始日期的行�����,然后檢索表中所有相鄰的行,直到到達結束日期����。這樣有助于提高此類查詢的性能���。同樣�,如果對從表中檢索的數據進行排序時經常要用到某一列�,則可以將該表在該列上聚集(物理排序),避免每次查詢該列時都進行排序�,從而節省成本�����。
非聚集索引與課本中的索引類似。數據存儲在一個地方�����,索引存儲在另一個地方����,索引帶有指針指向數據的存儲位置。索引中的項目按索引鍵值的順序存儲�����,而表中的信息按另一種順序存儲(這可以由聚集索引規定)�����。如果在表中未創建聚集索引,則無法保證這些行具有任何特定的順序。
更詳細的介紹請參考MSDN上關于索引的介紹。http://msdn.microsoft.com/zh-cn/library/ms189271.aspx
使用SQL Server的索引
問題又來了��,既然分了兩種索引��,何時何種情況用何種索引�����?那就看看下表吧。簡單的說就是:對于小數目的不同值,或列經常被分組排序����,或需要返回某范圍內的數據時使用聚集索引�;對于大數目的不同值��,或列經常被分組排序��,或列被頻繁更新時使用非聚集索引。
|
|
使用聚集索引
|
使用非聚集索引
|
|
列經常被分組排序
|
應
|
應
|
|
返回某范圍內的數據
|
應
|
不應
|
|
一個或極少不同值
|
不應
|
不應
|
|
小數目的不同值
|
應
|
不應
|
|
大數目的不同值
|
不應
|
應
|
|
頻繁更新的列
|
不應
|
應
|
|
外鍵列
|
應
|
應
|
|
主鍵列
|
應
|
應
|
|
頻繁修改索引列
|
不應
|
應
|
如何改善索引的一些經驗:
1. 索引首先要滿足你的應用中最關鍵或者是被很多用戶頻繁執行的查詢。
若某個查詢每月僅執行一次����,要考慮是否值得為其涉及表創建了索引����。要知道在當月的其它時間數據庫系統對該索引的維護開銷是要超過滿足該查詢的表掃描的開銷的����。所以���,好鋼用在刀刃上,好索引用在關鍵頻繁的查詢上��。
2. 在經常進行連接�,但是沒有指定為外鍵的列上建立索引。
在嵌套查詢中,對表的順序存取對查詢效率可能產生致命的影響����。比如采用順序存取策略����,一個嵌套3層的查詢�,如果每層都查詢1000行,那么這個查詢就要查詢10億行數據。避免這種情況的主要方法就是對連接的列進行索引�。例如下面的一條SQL�����,連接這兩個表:tblA(id, c1, c2, …)和tblB(id, …),就需要分別在兩個表的id字段上建立索引。
 select a.id, a.c1, a.c2, … from tblA a where exists (select 1 from tblB b where b.id = a.id)
select a.id, a.c1, a.c2, … from tblA a where exists (select 1 from tblB b where b.id = a.id)
3. 排序或分組對索引的影響
· 在頻繁進行排序或分組(即進行group by或order by操作)的列上建立索引��。如果待排序的列有多個�,可以在這些列上建立復合索引。
· 索引中一定要包含所有的group by或order by操作列���,且group by或order by操作列中列的次序一定要與索引中的次序相同。
· 簡化或避免對大數據量表的排序�。當能夠利用索引自動以適當的次序產生輸出時�,優化器就避免了排序的步驟�����。
· 排序的列若來自不同的表����,同樣會在執行計劃中引起一個排序的開銷��。為了避免不必要的排序���,就要正確地增建索引,合理地合并數據庫表(盡管有時可能影響表的規范化����,但相對于效率的提高是值得的)�����。如果排序不可避免,那么應當試圖簡化它�,如縮小排序的列的范圍等����。
4. 非黑即白就別索引了
在條件表達式中經常用到的不同值較多的列上建立非聚集索引�����,在不同值很少的列上就不要建立索引了��。比如在某表的“狀態”列上只有“是”與“否”兩個不同值,就沒必要建了���,因為此時表掃描來得更有效。若建了索引����,不但查詢效率沒提高����,反而嚴重降低了更新速度����。
5. “索引覆蓋”是怎樣煉成的
對某個表tblA建了個聚集索引tblA_idx(c1, c2, c3)。這樣實際上是建立了三個索引:(c1), (c1, c2), (c1, c2, c3)�。
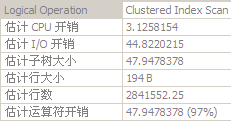
select min(c1) from tblA where c1 > 1 -- 會觸發Clustered Index Seek����。
select min(c1) from tblA where c1 > 1 and c2 = 2 -- 會觸發Clustered Index Seek��。
select min(c1) from tblA where c1 > 1 and c3 < 3 -- 會觸發Clustered Index Scan�。
select min(c1) from tblA where c2 = 2 and c3 < 3 -- 會觸發Clustered Index Scan���。
select min(c1) from tblA where c1 > 1 and c2 = 2 and c3 < 3 -- 會觸發Clustered Index Seek��,且形成了索引覆蓋����。
其中Clustered Index Scan的執行計劃

其中Clustered Index Seek的執行計劃

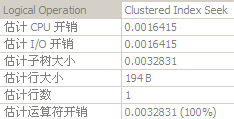
如此可見形成索引覆蓋的必要性�����。
6. 非聚集索引與精確查找的默契
對于某個表中的某個字段存在大數目的不同值時����,為該字段建個非聚集索引會達到意想不到的效果�。因為數據庫系統在搜索數據值時,先對非聚集索引進行搜索���,找到數據值在表中的位置,然后從該位置直接檢索數據����。因為索引包含描述查詢所搜索的數據值在表中的精確位置的條目�,這也是為什么非聚集索引是精確匹配查詢的最佳方法����。例如,在employee表為emp_id列建了非聚集索引�����,要搜索其雇員ID (emp_id) > 1000的所有人�����,SQL Server會在索引中直接跳到emp_id = 1000這樣一個條目之后,列出匹配的emp_id列在表中的頁和行,然后直接轉到該頁該行��。
7. 如果你是皮爾斯����,SQL Server 的執行計劃就是朗多
SQL Server 2005的Microsoft SQL Server Management Studio和Database Engine Tuning Advisor(DETA)是非常好的性能調試助手,可以使用它們對SQL語句調優,查看估計的執行計劃開銷�,用DETA生成優化建議����,采納或參考索引優化部分��。
需要注意的是�����,對于估計的執行計劃,不要過于關注里面顯示的開銷比例��,而實際上這個有時會誤導����。我在實際優化過程中就被發現,一個index scan的執行項開銷只占25%,另一個鍵查找的開銷占50%,而鍵查找部分根本沒有可優化的�,SEEK謂詞就是ID=XXX這個建立在主鍵上的查找����。而仔細分析可以看到���,后者CPU開銷0.00015��,I/O開銷0.0013。而前者呢�����,CPU開銷1.4xxxx,I/O開銷也遠大于后者����。因此�,優化重點應該放在前者����。
網上這類的文章很多,這里就不做贅述了�����?���?梢詤⒖家黄^早的文章:SQL Server性能調優入門(圖文版)
另外還有一篇不錯的文章,共享在這里:探討如何在有著1000萬條數據的MS SQL SERVER數據庫中實現快速的數據提取和數據分頁
THE END
posted on 2010-07-23 17:45
小立飛刀 閱讀(2815)
評論(0) 編輯 收藏 所屬分類:
Database