本文大部分內容都是從官網Hadoop上來的。其中有一篇介紹HDFS的pdf文檔,里面對Hadoop介紹的比較全面了。我的這一個系列的Hadoop學習筆記也是從這里一步一步進行下來的,同時又參考了網上的很多文章,對學習Hadoop中遇到的問題進行了歸納總結。
言歸正傳,先說一下Hadoop的來龍去脈。談到Hadoop就不得不提到Lucene和Nutch。首先,Lucene并不是一個應用程序,而是提供了一個純Java的高性能全文索引引擎工具包,它可以方便的嵌入到各種實際應用中實現全文搜索/索引功能。Nutch是一個應用程序,是一個以Lucene為基礎實現的搜索引擎應用,Lucene 為Nutch提供了文本搜索和索引的API,Nutch不光有搜索的功能,還有數據抓取的功能。在nutch0.8.0版本之前,Hadoop還屬于 Nutch的一部分,而從nutch0.8.0開始,將其中實現的NDFS和MapReduce剝離出來成立一個新的開源項目,這就是Hadoop,而 nutch0.8.0版本較之以前的Nutch在架構上有了根本性的變化,那就是完全構建在Hadoop的基礎之上了。在Hadoop中實現了 Google的GFS和MapReduce算法,使Hadoop成為了一個分布式的計算平臺。
其實,Hadoop并不僅僅是一個用于存儲的分布式文件系統,而是設計用來在由通用計算設備組成的大型集群上執行分布式應用的框架。
Hadoop包含兩個部分:
1、HDFS
即Hadoop Distributed File System (Hadoop分布式文件系統)
HDFS 具有高容錯性,并且可以被部署在低價的硬件設備之上。HDFS很適合那些有大數據集的應用,并且提供了對數據讀寫的高吞吐率。HDFS是一個 master/slave的結構,就通常的部署來說,在master上只運行一個Namenode,而在每一個slave上運行一個Datanode。
HDFS 支持傳統的層次文件組織結構,同現有的一些文件系統在操作上很類似,比如你可以創建和刪除一個文件,把一個文件從一個目錄移到另一個目錄,重命名等等操 作。Namenode管理著整個分布式文件系統,對文件系統的操作(如建立、刪除文件和文件夾)都是通過Namenode來控制。
下面是HDFS的結構:
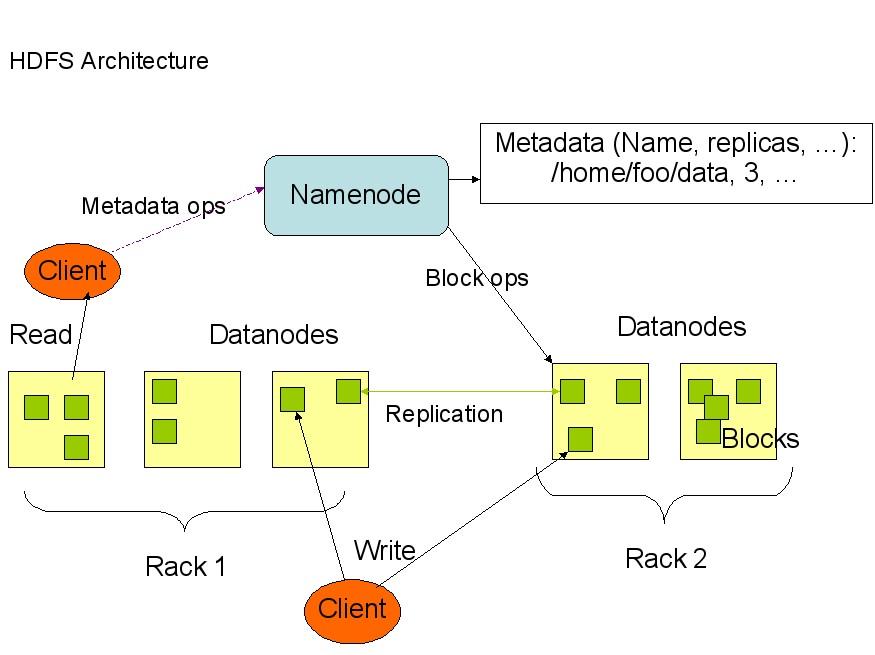
從上面的圖中可以看 出,Namenode,Datanode,Client之間的通信都是建立在TCP/IP的基礎之上的。當Client要執行一個寫入的操作的時候,命令 不是馬上就發送到Namenode,Client首先在本機上臨時文件夾中緩存這些數據,當臨時文件夾中的數據塊達到了設定的Block的值(默認是 64M)時,Client便會通知Namenode,Namenode便響應Client的RPC請求,將文件名插入文件系統層次中并且在 Datanode中找到一塊存放該數據的block,同時將該Datanode及對應的數據塊信息告訴Client,Client便這些本地臨時文件夾中 的數據塊寫入指定的數據節點。
HDFS采取了副本策略,其目的是為了提高系統的可靠性,可用性。HDFS的副本放置策略是三個副本, 一個放在本節點上,一個放在同一機架中的另一個節點上,還有一個副本放在另一個不同的機架中的一個節點上。當前版本的hadoop0.12.0中還沒有實 現,但是正在進行中,相信不久就可以出來了。
2、MapReduce的實現
MapReduce是Google 的一項重要技術,它是一個編程模型,用以進行大數據量的計算。對于大數據量的計算,通常采用的處理手法就是并行計算。至少現階段而言,對許多開發人員來 說,并行計算還是一個比較遙遠的東西。MapReduce就是一種簡化并行計算的編程模型,它讓那些沒有多少并行計算經驗的開發人員也可以開發并行應用。
MapReduce的名字源于這個模型中的兩項核心操作:Map和 Reduce。也許熟悉Functional Programming(函數式編程) 的人見到這兩個詞會倍感親切。簡單的說來,Map是把一組數據一對一的映射為另外的一組數據,其映射的規則由一個函數來指定,比如對[1, 2, 3, 4]進行乘2的映射就變成了[2, 4, 6, 8]。Reduce是對一組數據進行歸約,這個歸約的規則由一個函數指定,比如對[1, 2, 3, 4]進行求和的歸約得到結果是10,而對它進行求積的歸約結果是24。
關于MapReduce的內容,建議看看孟巖的這篇MapReduce:The Free Lunch Is Not Over!
好了,作為這個系列的第一篇就寫這么多了,我也是剛開始接觸Hadoop,下一篇就是講Hadoop的部署,談談我在部署Hadoop時遇到的問題,也給大家一個參考,少走點彎路。
]]>
Spring 不但提供了一個功能全面的應用開發框架,本身還擁有眾多可以在程序編寫時直接使用的工具類,您不但可以在 Spring 應用中使用這些工具類,也可以在其它的應用中使用,這些工具類中的大部分是可以在脫離 Spring 框架時使用的。了解 Spring 中有哪些好用的工具類并在程序編寫時適當使用,將有助于提高開發效率、增強代碼質量。
在這個分為兩部分的文章中,我們將從眾多的 Spring 工具類中遴選出那些好用的工具類介紹給大家。第 1 部分將介紹與文件資源操作和 Web 相關的工具類。在 第 2 部分 中將介紹特殊字符轉義和方法入參檢測工具類。
文件資源操作
文件資源的操作是應用程序中常見的功能,如當上傳一個文件后將其保存在特定目錄下,從指定地址加載一個配置文件等等。我們一般使用 JDK 的 I/O 處理類完成這些操作,但對于一般的應用程序來說,JDK 的這些操作類所提供的方法過于底層,直接使用它們進行文件操作不但程序編寫復雜而且容易產生錯誤。相比于 JDK 的 File,Spring 的 Resource 接口(資源概念的描述接口)抽象層面更高且涵蓋面更廣,Spring 提供了許多方便易用的資源操作工具類,它們大大降低資源操作的復雜度,同時具有更強的普適性。這些工具類不依賴于 Spring 容器,這意味著您可以在程序中象一般普通類一樣使用它們。
加載文件資源
Spring 定義了一個 org.springframework.core.io.Resource 接口,Resource 接口是為了統一各種類型不同的資源而定義的,Spring 提供了若干 Resource 接口的實現類,這些實現類可以輕松地加載不同類型的底層資源,并提供了獲取文件名、URL 地址以及資源內容的操作方法。
訪問文件資源
假設有一個文件地位于 Web 應用的類路徑下,您可以通過以下方式對這個文件資源進行訪問:
通過 FileSystemResource 以文件系統絕對路徑的方式進行訪問;
通過 ClassPathResource 以類路徑的方式進行訪問;
通過 ServletContextResource 以相對于Web應用根目錄的方式進行訪問。
相比于通過 JDK 的 File 類訪問文件資源的方式,Spring 的 Resource 實現類無疑提供了更加靈活的操作方式,您可以根據情況選擇適合的 Resource 實現類訪問資源。下面,我們分別通過 FileSystemResource 和 ClassPathResource 訪問同一個文件資源:
清單 1. FileSourceExample
package com.baobaotao.io;
import java.io.IOException;
import java.io.InputStream;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
public class FileSourceExample {
public static void main(String[] args) {
try {
String filePath =
"D:/masterSpring/chapter23/webapp/WEB-INF/classes/conf/file1.txt";
// ① 使用系統文件路徑方式加載文件
Resource res1 = new FileSystemResource(filePath);
// ② 使用類路徑方式加載文件
Resource res2 = new ClassPathResource("conf/file1.txt");
InputStream ins1 = res1.getInputStream();
InputStream ins2 = res2.getInputStream();
System.out.println("res1:"+res1.getFilename());
System.out.println("res2:"+res2.getFilename());
} catch (IOException e) {
e.printStackTrace();
}
}
}
在獲取資源后,您就可以通過 Resource 接口定義的多個方法訪問文件的數據和其它的信息:如您可以通過 getFileName() 獲取文件名,通過 getFile() 獲取資源對應的 File 對象,通過 getInputStream() 直接獲取文件的輸入流。此外,您還可以通過 createRelative(String relativePath) 在資源相對地址上創建新的資源。
在 Web 應用中,您還可以通過 ServletContextResource 以相對于 Web 應用根目錄的方式訪問文件資源,如下所示:
<%@ page language="java" contentType="text/html; charset=utf-8" pageEncoding="utf-8"%>
<jsp:directive.page import="
org.springframework.web.context.support.ServletContextResource"/>
<jsp:directive.page import="org.springframework.core.io.Resource"/>
<%
// ① 注意文件資源地址以相對于 Web 應用根路徑的方式表示
Resource res3 = new ServletContextResource(application,
"/WEB-INF/classes/conf/file1.txt");
out.print(res3.getFilename());
%>
對于位于遠程服務器(Web 服務器或 FTP 服務器)的文件資源,您則可以方便地通過 UrlResource 進行訪問。
為了方便訪問不同類型的資源,您必須使用相應的 Resource 實現類,是否可以在不顯式使用 Resource 實現類的情況下,僅根據帶特殊前綴的資源地址直接加載文件資源呢?Spring 提供了一個 ResourceUtils 工具類,它支持“classpath:”和“file:”的地址前綴,它能夠從指定的地址加載文件資源,請看下面的例子:
清單 2. ResourceUtilsExample
package com.baobaotao.io;
import java.io.File;
import org.springframework.util.ResourceUtils;
public class ResourceUtilsExample {
public static void main(String[] args) throws Throwable{
File clsFile = ResourceUtils.getFile("classpath:conf/file1.txt");
System.out.println(clsFile.isFile());
String httpFilePath = "file:D:/masterSpring/chapter23/src/conf/file1.txt";
File httpFile = ResourceUtils.getFile(httpFilePath);
System.out.println(httpFile.isFile());
}
}
ResourceUtils 的 getFile(String resourceLocation) 方法支持帶特殊前綴的資源地址,這樣,我們就可以在不和 Resource 實現類打交道的情況下使用 Spring 文件資源加載的功能了。
本地化文件資源
本地化文件資源是一組通過本地化標識名進行特殊命名的文件,Spring 提供的 LocalizedResourceHelper 允許通過文件資源基名和本地化實體獲取匹配的本地化文件資源并以 Resource 對象返回。假設在類路徑的 i18n 目錄下,擁有一組基名為 message 的本地化文件資源,我們通過以下實例演示獲取對應中國大陸和美國的本地化文件資源:
清單 3. LocaleResourceTest
package com.baobaotao.io;
import java.util.Locale;
import org.springframework.core.io.Resource;
import org.springframework.core.io.support.LocalizedResourceHelper;
public class LocaleResourceTest {
public static void main(String[] args) {
LocalizedResourceHelper lrHalper = new LocalizedResourceHelper();
// ① 獲取對應美國的本地化文件資源
Resource msg_us = lrHalper.findLocalizedResource("i18n/message", ".properties",
Locale.US);
// ② 獲取對應中國大陸的本地化文件資源
Resource msg_cn = lrHalper.findLocalizedResource("i18n/message", ".properties",
Locale.CHINA);
System.out.println("fileName(us):"+msg_us.getFilename());
System.out.println("fileName(cn):"+msg_cn.getFilename());
}
}
雖然 JDK 的 java.util.ResourceBundle 類也可以通過相似的方式獲取本地化文件資源,但是其返回的是 ResourceBundle 類型的對象。如果您決定統一使用 Spring 的 Resource 接表征文件資源,那么 LocalizedResourceHelper 就是獲取文件資源的非常適合的幫助類了。
文件操作
在使用各種 Resource 接口的實現類加載文件資源后,經常需要對文件資源進行讀取、拷貝、轉存等不同類型的操作。您可以通過 Resource 接口所提供了方法完成這些功能,不過在大多數情況下,通過 Spring 為 Resource 所配備的工具類完成文件資源的操作將更加方便。
文件內容拷貝
第一個我們要認識的是 FileCopyUtils,它提供了許多一步式的靜態操作方法,能夠將文件內容拷貝到一個目標 byte[]、String 甚至一個輸出流或輸出文件中。下面的實例展示了 FileCopyUtils 具體使用方法:
清單 4. FileCopyUtilsExample
package com.baobaotao.io;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileReader;
import java.io.OutputStream;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;
import org.springframework.util.FileCopyUtils;
public class FileCopyUtilsExample {
public static void main(String[] args) throws Throwable {
Resource res = new ClassPathResource("conf/file1.txt");
// ① 將文件內容拷貝到一個 byte[] 中
byte[] fileData = FileCopyUtils.copyToByteArray(res.getFile());
// ② 將文件內容拷貝到一個 String 中
String fileStr = FileCopyUtils.copyToString(new FileReader(res.getFile()));
// ③ 將文件內容拷貝到另一個目標文件
FileCopyUtils.copy(res.getFile(),
new File(res.getFile().getParent()+ "/file2.txt"));
// ④ 將文件內容拷貝到一個輸出流中
OutputStream os = new ByteArrayOutputStream();
FileCopyUtils.copy(res.getInputStream(), os);
}
}
往往我們都通過直接操作 InputStream 讀取文件的內容,但是流操作的代碼是比較底層的,代碼的面向對象性并不強。通過 FileCopyUtils 讀取和拷貝文件內容易于操作且相當直觀。如在 ① 處,我們通過 FileCopyUtils 的 copyToByteArray(File in) 方法就可以直接將文件內容讀到一個 byte[] 中;另一個可用的方法是 copyToByteArray(InputStream in),它將輸入流讀取到一個 byte[] 中。
如果是文本文件,您可能希望將文件內容讀取到 String 中,此時您可以使用 copyToString(Reader in) 方法,如 ② 所示。使用 FileReader 對 File 進行封裝,或使用 InputStreamReader 對 InputStream 進行封裝就可以了。
FileCopyUtils 還提供了多個將文件內容拷貝到各種目標對象中的方法,這些方法包括:
方法 說明
static void copy(byte[] in, File out) 將 byte[] 拷貝到一個文件中
static void copy(byte[] in, OutputStream out) 將 byte[] 拷貝到一個輸出流中
static int copy(File in, File out) 將文件拷貝到另一個文件中
static int copy(InputStream in, OutputStream out) 將輸入流拷貝到輸出流中
static int copy(Reader in, Writer out) 將 Reader 讀取的內容拷貝到 Writer 指向目標輸出中
static void copy(String in, Writer out) 將字符串拷貝到一個 Writer 指向的目標中
在實例中,我們雖然使用 Resource 加載文件資源,但 FileCopyUtils 本身和 Resource 沒有任何關系,您完全可以在基于 JDK I/O API 的程序中使用這個工具類。
屬性文件操作
我們知道可以通過 java.util.Properties的load(InputStream inStream) 方法從一個輸入流中加載屬性資源。Spring 提供的 PropertiesLoaderUtils 允許您直接通過基于類路徑的文件地址加載屬性資源,請看下面的例子:
package com.baobaotao.io;
import java.util.Properties;
import org.springframework.core.io.support.PropertiesLoaderUtils;
public class PropertiesLoaderUtilsExample {
public static void main(String[] args) throws Throwable {
// ① jdbc.properties 是位于類路徑下的文件
Properties props = PropertiesLoaderUtils.loadAllProperties("jdbc.properties");
System.out.println(props.getProperty("jdbc.driverClassName"));
}
}
一般情況下,應用程序的屬性文件都放置在類路徑下,所以 PropertiesLoaderUtils 比之于 Properties#load(InputStream inStream) 方法顯然具有更強的實用性。此外,PropertiesLoaderUtils 還可以直接從 Resource 對象中加載屬性資源:
方法 說明
static Properties loadProperties(Resource resource) 從 Resource 中加載屬性
static void fillProperties(Properties props, Resource resource) 將 Resource 中的屬性數據添加到一個已經存在的 Properties 對象中
特殊編碼的資源
當您使用 Resource 實現類加載文件資源時,它默認采用操作系統的編碼格式。如果文件資源采用了特殊的編碼格式(如 UTF-8),則在讀取資源內容時必須事先通過 EncodedResource 指定編碼格式,否則將會產生中文亂碼的問題。
清單 5. EncodedResourceExample
package com.baobaotao.io;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;
import org.springframework.core.io.support.EncodedResource;
import org.springframework.util.FileCopyUtils;
public class EncodedResourceExample {
public static void main(String[] args) throws Throwable {
Resource res = new ClassPathResource("conf/file1.txt");
// ① 指定文件資源對應的編碼格式(UTF-8)
EncodedResource encRes = new EncodedResource(res,"UTF-8");
// ② 這樣才能正確讀取文件的內容,而不會出現亂碼
String content = FileCopyUtils.copyToString(encRes.getReader());
System.out.println(content);
}
}
EncodedResource 擁有一個 getResource() 方法獲取 Resource,但該方法返回的是通過構造函數傳入的原 Resource 對象,所以必須通過 EncodedResource#getReader() 獲取應用編碼后的 Reader 對象,然后再通過該 Reader 讀取文件的內容。
回頁首
Web 相關工具類
您幾乎總是使用 Spring 框架開發 Web 的應用,Spring 為 Web 應用提供了很多有用的工具類,這些工具類可以給您的程序開發帶來很多便利。在這節里,我們將逐一介紹這些工具類的使用方法。
操作 Servlet API 的工具類
當您在控制器、JSP 頁面中想直接訪問 Spring 容器時,您必須事先獲取 WebApplicationContext 對象。Spring 容器在啟動時將 WebApplicationContext 保存在 ServletContext的屬性列表中,通過 WebApplicationContextUtils 工具類可以方便地獲取 WebApplicationContext 對象。
WebApplicationContextUtils
當 Web 應用集成 Spring 容器后,代表 Spring 容器的 WebApplicationContext 對象將以 WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE 為鍵存放在 ServletContext 屬性列表中。您當然可以直接通過以下語句獲取 WebApplicationContext:
WebApplicationContext wac = (WebApplicationContext)servletContext.
getAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE);
但通過位于 org.springframework.web.context.support 包中的 WebApplicationContextUtils 工具類獲取 WebApplicationContext 更方便:
WebApplicationContext wac =WebApplicationContextUtils.
getWebApplicationContext(servletContext);
當 ServletContext 屬性列表中不存在 WebApplicationContext 時,getWebApplicationContext() 方法不會拋出異常,它簡單地返回 null。如果后續代碼直接訪問返回的結果將引發一個 NullPointerException 異常,而 WebApplicationContextUtils 另一個 getRequiredWebApplicationContext(ServletContext sc) 方法要求 ServletContext 屬性列表中一定要包含一個有效的 WebApplicationContext 對象,否則馬上拋出一個 IllegalStateException 異常。我們推薦使用后者,因為它能提前發現錯誤的時間,強制開發者搭建好必備的基礎設施。
WebUtils
位于 org.springframework.web.util 包中的 WebUtils 是一個非常好用的工具類,它對很多 Servlet API 提供了易用的代理方法,降低了訪問 Servlet API 的復雜度,可以將其看成是常用 Servlet API 方法的門面類。
下面這些方法為訪問 HttpServletRequest 和 HttpSession 中的對象和屬性帶來了方便:
方法 說明
Cookie getCookie(HttpServletRequest request, String name) 獲取 HttpServletRequest 中特定名字的 Cookie 對象。如果您需要創建 Cookie, Spring 也提供了一個方便的 CookieGenerator 工具類;
Object getSessionAttribute(HttpServletRequest request, String name) 獲取 HttpSession 特定屬性名的對象,否則您必須通過request.getHttpSession.getAttribute(name) 完成相同的操作;
Object getRequiredSessionAttribute(HttpServletRequest request, String name) 和上一個方法類似,只不過強制要求 HttpSession 中擁有指定的屬性,否則拋出異常;
String getSessionId(HttpServletRequest request) 獲取 Session ID 的值;
void exposeRequestAttributes(ServletRequest request, Map attributes) 將 Map 元素添加到 ServletRequest 的屬性列表中,當請求被導向(forward)到下一個處理程序時,這些請求屬性就可以被訪問到了;
此外,WebUtils還提供了一些和ServletContext相關的方便方法:
方法 說明
String getRealPath(ServletContext servletContext, String path) 獲取相對路徑對應文件系統的真實文件路徑;
File getTempDir(ServletContext servletContext) 獲取 ServletContex 對應的臨時文件地址,它以 File 對象的形式返回。
下面的片斷演示了使用 WebUtils 從 HttpSession 中獲取屬性對象的操作:
protected Object formBackingObject(HttpServletRequest request) throws Exception {
UserSession userSession = (UserSession) WebUtils.getSessionAttribute(request,
"userSession");
if (userSession != null) {
return new AccountForm(this.petStore.getAccount(
userSession.getAccount().getUsername()));
} else {
return new AccountForm();
}
}
Spring 所提供的過濾器和監聽器
Spring 為 Web 應用提供了幾個過濾器和監聽器,在適合的時間使用它們,可以解決一些常見的 Web 應用問題。
延遲加載過濾器
Hibernate 允許對關聯對象、屬性進行延遲加載,但是必須保證延遲加載的操作限于同一個 Hibernate Session 范圍之內進行。如果 Service 層返回一個啟用了延遲加載功能的領域對象給 Web 層,當 Web 層訪問到那些需要延遲加載的數據時,由于加載領域對象的 Hibernate Session 已經關閉,這些導致延遲加載數據的訪問異常。
Spring 為此專門提供了一個 OpenSessionInViewFilter 過濾器,它的主要功能是使每個請求過程綁定一個 Hibernate Session,即使最初的事務已經完成了,也可以在 Web 層進行延遲加載的操作。
OpenSessionInViewFilter 過濾器將 Hibernate Session 綁定到請求線程中,它將自動被 Spring 的事務管理器探測到。所以 OpenSessionInViewFilter 適用于 Service 層使用HibernateTransactionManager 或 JtaTransactionManager 進行事務管理的環境,也可以用于非事務只讀的數據操作中。
要啟用這個過濾器,必須在 web.xml 中對此進行配置:
…
<filter>
<filter-name>hibernateFilter</filter-name>
<filter-class>
org.springframework.orm.hibernate3.support.OpenSessionInViewFilter
</filter-class>
</filter>
<filter-mapping>
<filter-name>hibernateFilter</filter-name>
<url-pattern>*.html</url-pattern>
</filter-mapping>
…
上面的配置,我們假設使用 .html 的后綴作為 Web 框架的 URL 匹配模式,如果您使用 Struts 等 Web 框架,可以將其改為對應的“*.do”模型。
中文亂碼過濾器
在您通過表單向服務器提交數據時,一個經典的問題就是中文亂碼問題。雖然我們所有的 JSP 文件和頁面編碼格式都采用 UTF-8,但這個問題還是會出現。解決的辦法很簡單,我們只需要在 web.xml 中配置一個 Spring 的編碼轉換過濾器就可以了:
<web-app>
<!---listener的配置-->
<filter>
<filter-name>encodingFilter</filter-name>
<filter-class>
org.springframework.web.filter.CharacterEncodingFilter ① Spring 編輯過濾器
</filter-class>
<init-param> ② 編碼方式
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
<init-param> ③ 強制進行編碼轉換
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>
</filter>
<filter-mapping> ② 過濾器的匹配 URL
<filter-name>encodingFilter</filter-name>
<url-pattern>*.html</url-pattern>
</filter-mapping>
<!---servlet的配置-->
</web-app>
這樣所有以 .html 為后綴的 URL 請求的數據都會被轉碼為 UTF-8 編碼格式,表單中文亂碼的問題就可以解決了。
請求跟蹤日志過濾器
除了以上兩個常用的過濾器外,還有兩個在程序調試時可能會用到的請求日志跟蹤過濾器,它們會將請求的一些重要信息記錄到日志中,方便程序的調試。這兩個日志過濾器只有在日志級別為 DEBUG 時才會起作用:
方法 說明
org.springframework.web.filter.ServletContextRequestLoggingFilter 該過濾器將請求的 URI 記錄到 Common 日志中(如通過 Log4J 指定的日志文件);
org.springframework.web.filter.ServletContextRequestLoggingFilter 該過濾器將請求的 URI 記錄到 ServletContext 日志中。
以下是日志過濾器記錄的請求跟蹤日志的片斷:
(JspServlet.java:224) - JspEngine --> /htmlTest.jsp
(JspServlet.java:225) - ServletPath: /htmlTest.jsp
(JspServlet.java:226) - PathInfo: null
(JspServlet.java:227) - RealPath: D:\masterSpring\chapter23\webapp\htmlTest.jsp
(JspServlet.java:228) - RequestURI: /baobaotao/htmlTest.jsp
…
通過這個請求跟蹤日志,程度調試者可以詳細地查看到有哪些請求被調用,請求的參數是什么,請求是否正確返回等信息。雖然這兩個請求跟蹤日志過濾器一般在程序調試時使用,但是即使程序部署不將其從 web.xml 中移除也不會有大礙,因為只要將日志級別設置為 DEBUG 以上級別,它們就不會輸出請求跟蹤日志信息了。
轉存 Web 應用根目錄監聽器和 Log4J 監聽器
Spring 在 org.springframework.web.util 包中提供了幾個特殊用途的 Servlet 監聽器,正確地使用它們可以完成一些特定需求的功能。比如某些第三方工具支持通過 ${key} 的方式引用系統參數(即可以通過 System.getProperty() 獲取的屬性),WebAppRootListener 可以將 Web 應用根目錄添加到系統參數中,對應的屬性名可以通過名為“webAppRootKey”的 Servlet 上下文參數指定,默認為“webapp.root”。下面是該監聽器的具體的配置:
清單 6. WebAppRootListener 監聽器配置
…
<context-param>
<param-name>webAppRootKey</param-name>
<param-value>baobaotao.root</param-value> ① Web 應用根目錄以該屬性名添加到系統參數中
</context-param>
…
② 負責將 Web 應用根目錄以 webAppRootKey 上下文參數指定的屬性名添加到系統參數中
<listener>
<listener-class>
org.springframework.web.util.WebAppRootListener
</listener-class>
</listener>
…
這樣,您就可以在程序中通過 System.getProperty("baobaotao.root") 獲取 Web 應用的根目錄了。不過更常見的使用場景是在第三方工具的配置文件中通過${baobaotao.root} 引用 Web 應用的根目錄。比如以下的 log4j.properties 配置文件就通過 ${baobaotao.root} 設置了日志文件的地址:
log4j.rootLogger=INFO,R
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=${baobaotao.root}/WEB-INF/logs/log4j.log ① 指定日志文件的地址
log4j.appender.R.MaxFileSize=100KB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout.ConversionPattern=%d %5p [%t] (%F:%L) - %m%n
另一個專門用于 Log4J 的監聽器是 Log4jConfigListener。一般情況下,您必須將 Log4J 日志配置文件以 log4j.properties 為文件名并保存在類路徑下。Log4jConfigListener 允許您通過 log4jConfigLocation Servlet 上下文參數顯式指定 Log4J 配置文件的地址,如下所示:
① 指定 Log4J 配置文件的地址
<context-param>
<param-name>log4jConfigLocation</param-name>
<param-value>/WEB-INF/log4j.properties</param-value>
</context-param>
…
② 使用該監聽器初始化 Log4J 日志引擎
<listener>
<listener-class>
org.springframework.web.util.Log4jConfigListener
</listener-class>
</listener>
…
提示
一些Web應用服務器(如 Tomcat)不會為不同的Web應用使用獨立的系統參數,也就是說,應用服務器上所有的 Web 應用都共享同一個系統參數對象。這時,您必須通過webAppRootKey 上下文參數為不同Web應用指定不同的屬性名:如第一個 Web 應用使用 webapp1.root 而第二個 Web 應用使用 webapp2.root 等,這樣才不會發生后者覆蓋前者的問題。此外,WebAppRootListener 和 Log4jConfigListener 都只能應用在 Web 應用部署后 WAR 文件會解包的 Web 應用服務器上。一些 Web 應用服務器不會將Web 應用的 WAR 文件解包,整個 Web 應用以一個 WAR 包的方式存在(如 Weblogic),此時因為無法指定對應文件系統的 Web 應用根目錄,使用這兩個監聽器將會發生問題。
Log4jConfigListener 監聽器包括了 WebAppRootListener 的功能,也就是說,Log4jConfigListener 會自動完成將 Web 應用根目錄以 webAppRootKey 上下文參數指定的屬性名添加到系統參數中,所以當您使用 Log4jConfigListener 后,就沒有必須再使用 WebAppRootListener了。
Introspector 緩存清除監聽器
Spring 還提供了一個名為 org.springframework.web.util.IntrospectorCleanupListener 的監聽器。它主要負責處理由 JavaBean Introspector 功能而引起的緩存泄露。IntrospectorCleanupListener 監聽器在 Web 應用關閉的時會負責清除 JavaBean Introspector 的緩存,在 web.xml 中注冊這個監聽器可以保證在 Web 應用關閉的時候釋放與其相關的 ClassLoader 的緩存和類引用。如果您使用了 JavaBean Introspector 分析應用中的類,Introspector 緩存會保留這些類的引用,結果在應用關閉的時候,這些類以及Web 應用相關的 ClassLoader 不能被垃圾回收。不幸的是,清除 Introspector 的唯一方式是刷新整個緩存,這是因為沒法準確判斷哪些是屬于本 Web 應用的引用對象,哪些是屬于其它 Web 應用的引用對象。所以刪除被緩存的 Introspection 會導致將整個 JVM 所有應用的 Introspection 都刪掉。需要注意的是,Spring 托管的 Bean 不需要使用這個監聽器,因為 Spring 的 Introspection 所使用的緩存在分析完一個類之后會馬上從 javaBean Introspector 緩存中清除掉,并將緩存保存在應用程序特定的 ClassLoader 中,所以它們一般不會導致內存資源泄露。但是一些類庫和框架往往會產生這個問題。例如 Struts 和 Quartz 的 Introspector 的內存泄漏會導致整個的 Web 應用的 ClassLoader 不能進行垃圾回收。在 Web 應用關閉之后,您還會看到此應用的所有靜態類引用,這個錯誤當然不是由這個類自身引起的。解決這個問題的方法很簡單,您僅需在 web.xml 中配置 IntrospectorCleanupListener 監聽器就可以了:
<listener>
<listener-class>
org.springframework.web.util.IntrospectorCleanupListener
</listener-class>
</listener>
回頁首
小結
本文介紹了一些常用的 Spring 工具類,其中大部分 Spring 工具類不但可以在基于 Spring 的應用中使用,還可以在其它的應用中使用。使用 JDK 的文件操作類在訪問類路徑相關、Web 上下文相關的文件資源時,往往顯得拖泥帶水、拐彎抹角,Spring 的 Resource 實現類使這些工作變得輕松了許多。
在 Web 應用中,有時你希望直接訪問 Spring 容器,獲取容器中的 Bean,這時使用 WebApplicationContextUtils 工具類從 ServletContext 中獲取 WebApplicationContext 是非常方便的。WebUtils 為訪問 Servlet API 提供了一套便捷的代理方法,您可以通過 WebUtils 更好的訪問 HttpSession 或 ServletContext 的信息。
Spring 提供了幾個 Servlet 過濾器和監聽器,其中 ServletContextRequestLoggingFilter 和 ServletContextRequestLoggingFilter 可以記錄請求訪問的跟蹤日志,你可以在程序調試時使用它們獲取請求調用的詳細信息。WebAppRootListener 可以將 Web 應用的根目錄以特定屬性名添加到系統參數中,以便第三方工具類通過 ${key} 的方式進行訪問。Log4jConfigListener 允許你指定 Log4J 日志配置文件的地址,且可以在配置文件中通過 ${key} 的方式引用 Web 應用根目錄,如果你需要在 Web 應用相關的目錄創建日志文件,使用 Log4jConfigListener 可以很容易地達到這一目標。
Web 應用的內存泄漏是最讓開發者頭疼的問題,雖然不正確的程序編寫可能是這一問題的根源,也有可能是一些第三方框架的 JavaBean Introspector 緩存得不到清除而導致的,Spring 專門為解決這一問題配備了 IntrospectorCleanupListener 監聽器,它只要簡單在 web.xml 中聲明該監聽器就可以了。
]]>
|
方法 |
說明 |
|
Restrictions.eq |
= |
|
Restrictions.allEq |
利用Map來進行多個等于的限制 |
|
Restrictions.gt |
> |
|
Restrictions.ge |
>= |
|
Restrictions.lt |
< |
|
Restrictions.le |
<= |
|
Restrictions.between |
BETWEEN |
|
Restrictions.like |
LIKE |
|
Restrictions.in |
in |
|
Restrictions.and |
and |
|
Restrictions.or |
or |
|
Restrictions.sqlRestriction |
用SQL限定查詢 |
QBC常用限定方法
Restrictions.eq --> equal,等于.
Restrictions.allEq --> 參數為Map對象,使用key/value進行多個等于的比對,相當于多個Restrictions.eq 的效果
Restrictions.gt --> great-than > 大于
Restrictions.ge --> great-equal >= 大于等于
Restrictions.lt --> less-than, < 小于
Restrictions.le --> less-equal <= 小于等于
Restrictions.between --> 對應SQL的between子句
Restrictions.like --> 對應SQL的LIKE子句
Restrictions.in --> 對應SQL的in子句
Restrictions.and --> and 關系
Restrictions.or --> or 關系
Restrictions.isNull --> 判斷屬性是否為空,為空則返回true
Restrictions.isNotNull --> 與isNull相反
Restrictions.sqlRestriction --> SQL限定的查詢
Order.asc --> 根據傳入的字段進行升序排序
Order.desc --> 根據傳入的字段進行降序排序
MatchMode.EXACT --> 字符串精確匹配.相當于"like 'value'"
MatchMode.ANYWHERE --> 字符串在中間匹配.相當于"like '%value%'"
MatchMode.START --> 字符串在最前面的位置.相當于"like 'value%'"
MatchMode.END --> 字符串在最后面的位置.相當于"like '%value'"
例子
查詢年齡在20-30歲之間的所有學生對象
List list = session.createCriteria(Student.class)
.add(Restrictions.between("age",new Integer(20),new Integer(30)).list();
查詢學生姓名在AAA,BBB,CCC之間的學生對象
String[] names = {"AAA","BBB","CCC"};
List list = session.createCriteria(Student.class)
.add(Restrictions.in("name",names)).list();
查詢年齡為空的學生對象
List list = session.createCriteria(Student.class)
.add(Restrictions.isNull("age")).list();
查詢年齡等于20或者年齡為空的學生對象
List list = session.createCriteria(Student.class)
.add(Restrictions.or(Restrictions.eq("age",new Integer(20)),
Restrictions.isNull("age")).list();
--------------------------------------------------------------------
使用QBC實現動態查詢
public List findStudents(String name,int age){
Criteria criteria = session.createCriteria(Student.class);
if(name != null){
criteria.add(Restrictions.liek("name",name,MatchMode.ANYWHERE));
}
if(age != 0){
criteria.add(Restrictions.eq("age",new Integer(age)));
}
criteria.addOrder(Order.asc("name"));//根據名字升序排列
return criteria.list();
}
-----------------------------------------------------------------------------------
今天用了寫hibernate高級查詢時用了Restrictions(當然Expr
下面的代碼寫的不易讀.其實核心就是一句
Restrictions.or(Restrictions.like(),Restrictions.or(Restrictions.like,........))
里面的or可以無限加的.還是比較好用
Session session = getHibernateTemplate().getSessionFactory()
.openSession();
Criteria criteria = session.createCriteria(Film.class);
List<Film> list = criteria.add(
Restrictions.or(Restrictions.like("description", key,MatchMode.ANYWHERE),
Restrictions.or(Restrictions.like("name", key,MatchMode.ANYWHERE),
Restrictions.or( Restrictions.like("direct", key,MatchMode.ANYWHERE),
Restrictions.or(Restrictions.like("mainplay",key,MatchMode.ANYWHERE),
Restrictions.like("filearea", key,MatchMode.ANYWHERE)))))).list();
session.close();
return list;
]]>
當網絡爬蟲將網頁下載到磁盤上以后,需要對這些網頁中的內容進行抽取,為索引做準備。一個網頁中的數據大部分是HTML標簽,索引肯定不會去索引這些標簽。也就是說,這種信息是沒有用處的信息,需要在抽取過程中過濾掉。另外,一個網頁中一般會存在廣告信息、錨文本信息,還有一些我們不感興趣的信息,都被視為垃圾信息,如果不加考慮這些內容,抽取出來的信息不僅占用存儲空間,而且在索引以后,為終端用戶提供檢索服務,用戶檢會索到很多無用的垃圾信息,勢必影響用戶的體驗。
這里,針對論壇,采用配置模板的方式來實現信息的抽取。使用的工具可以到http://jregex.sourceforge.net上下載,JRegex是一個基于Java的正則庫,可以通過在正則模板中指定待抽取信息的變量,在抽取過程中會將抽取到的信息賦給該變量,從而得到感興趣的信息。而且,JRegex庫支持多級分組匹配。
為了直觀,假設,有一個論壇的一個網頁的源代碼形如:
<a id="anchor">標題</a>
<cont>
<author>a1</author>
<time>2009</time>
<post>p1</post>
<author>a2</author>
<time>2008</time>
<post>p2</post>
<author>a3</author>
<time>2007</time>
<post>p3</post>
<author>a4</author>
<time>2006</time>
<post>p4</post>
<author>2005</author>
<time>t5</time>
<post>p5</post>
</cont>
將該網頁代碼文件保存為bbsPage.txt文件,準備進行處理。
現在,我們的目標是抽取標題、作者、時間、內容這些內容,當然,標題完全可以從TITLE標簽中獲得,但是一般網站的一個網頁,會在標題文本的后面加上一些目錄或者網站名稱的信息,例如一個標題為“品味北京奧運中心_奧運加油站_我行我攝_XXX社區_XXX社區是最活躍的社區之一”,一些垃圾信息占了標題的大部分,所以我們不從TITLE標簽中抽取標題。
接著,針對上面的網頁文件創建信息抽取的正則模板,如下所示:
(?s)<a\sid="anchor">({title}.{1,100}?)</a>\s*<cont>(.{1,10240}?)</cont> <author>({name}.{1,100}?)</author>\s*<time>({when}.{1,100}?)</time>\s*<post>({content}.{1,100}?)</post>
該模板包含兩部分:
第一部分為(?s)<a\sid="anchor">({title}.{1,100}?)</a>\s*<cont>(.{1,10240}?)</cont>,包含兩個組,第一個組名稱為title,直接能夠抽取到網頁的標題文本,并存儲到變量title中;而第二個組沒有指定組的名稱,表示在后面還存在子組,在子組中繼續進行抽取。
第二部分為<author>({name}.{1,100}?)</author>\s*<time>({when}.{1,100}?)</time>\s*<post>({content}.{1,100}?)</post>,恰好是父組中未指定組名稱的第二個組內中的一個循環。
上面兩個模板之間使用一個空格字符隔開,保存到pattern.txt文件中。
可能,你已經觀察到了,網頁的標題只有一個,而對其他的信息正好能夠構成一個循環組,單獨從父組中分離出來繼續進行抽取,結構很整齊。所以,在使用JRegex庫進行編碼抽取的時候,主要就是針對兩個組進行的。
我基于上面思想和數據,實現了信息的抽取。
首先定義了一個鍵值對實體類,使用泛型,如下所示:
package org.shirdrn.test;
public class Pair<K, V> {
private K key;
private V value;
public Pair(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
}
進行信息抽取的核心類為InfomationExtraction,如下所示:
package org.shirdrn.test;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
import jregex.Matcher;
import jregex.Pattern;
public class InfomationExtraction {
private String htmlString;
private String patternString;
private List<Pair<String, String>> dataList = new ArrayList<Pair<String, String>>();
public InfomationExtraction() {
}
public InfomationExtraction(String htmlFileName, String patternFileName) {
this.htmlString = this.readString(htmlFileName);
this.patternString = this.readString(patternFileName);
}
public Pattern[] getPatternArray() {
Pattern[] pa = new Pattern[2];
String[] psa = this.patternString.split(" ");
for(int i=0; i<psa.length; i++) {
Pattern p = new Pattern(psa[i]);
pa[i] = p;
}
return pa;
}
public void extract(Integer sgIndex) { // 指定父組中第sgIndex個組需要在子組中繼續進行抽取
Pattern[] pa = this.getPatternArray();
Pattern pBase = pa[0];
Matcher mBase = pBase.matcher(this.htmlString);
if(mBase.find()) {
for(int i=0; i<mBase.groupCount(); i++) {
String gn = pBase.groupName(i);
if(gn != null) {
String gv = mBase.group(i);
this.dataList.add(new Pair<String, String>(gn, gv));
}
}
String subText = mBase.group(sgIndex);
if(subText != null) {
this.dataList.addAll(this.getSubGroupDataList(pa, subText)); // 調用使用子組正則模板進行抽取的方法
}
}
}
public List<Pair<String, String>> getSubGroupDataList(Pattern[] pa, String subText) { // 使用子組正則模板進行抽取
List<Pair<String, String>> list = new ArrayList<Pair<String, String>>();
for(int i=1; i<pa.length; i++) {
Pattern subp =pa[i];
Matcher subm = subp.matcher(subText);
while(subm.find()) {
for(int k=0; k<subm.groupCount(); k++) {
String gn = subp.groupName(k);
if(gn != null) {
String gv = subm.group(k);
list.add(new Pair<String, String>(gn, gv));
}
}
}
}
return list;
}
public String readString(String fileName) {
InputStream in = this.getClass().getResourceAsStream("/" + fileName);
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
StringBuffer sb = new StringBuffer();
String line = null;
try {
while((line=reader.readLine()) != null) {
sb.append(line);
}
} catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
public List<Pair<String, String>> getDataList() {
return this.dataList;
}
public static void main(String[] args) {
InfomationExtraction ie = new InfomationExtraction("bbsPage.txt","pattern.txt");
ie.extract(2);
for(Pair<String, String> p : ie.getDataList()) {
System.out.println("[" + p.getKey() + " " + p.getValue() + "]");
}
}
}
測試一下,如下所示:
[title 標題]
[name a1]
[when 2009]
[content p1]
[name a2]
[when 2008]
[content p2]
[name a3]
[when 2007]
[content p3]
[name a4]
[when 2006]
[content p4]
[name 2005]
[when t5]
[content p5]
至于如何組織抽取到的信息,比如你可能使用Lucene的索引,需要構造Field和Document,那么你就要設計一個實體能夠包含一個Document的所有的Field,比如一個Document包括:URL、標題、作者、發表時間、發表內容這五個項,非常容易就能做到。
使用JRegex庫,可以非常靈活地配置模板,尤其是對多個組的設計,這要根據你的需要來考慮。
]]>
希望這篇文章可以對OpenCms的追隨者們有所幫助,但這也只是OpenCms的皮毛,把它的強大功能為已所用還需要我們付出更多的努力……
一、切換到“/sites/”下,創建站點文件夾“testWeb”


輸入文件夾的標題,這個標題就是站點的名稱,一會兒你就會看到它的用處,它會顯示在“站點”下……

創建后的結果如下:

二、配置tomcat,打開tomcat\conf\server.xml文件,增加如下藍色選中區內容:

三、打開tomcat\webapps\cms623\WEB-INF\config\opencms-system.xml,增加如下藍色選中區內容:

四、重啟tomat,登陸到OpenCms,這時在“站點”列表框中就會出現我們創建的網站“我的測試站點”,發,如下圖:

切換到“我的測試站點”,顯示如下圖,這就是我們網站的“根目錄”了……

五、創建網站模塊:

創建模板內容如下:
 <%@ taglib prefix="cms" uri="http://www.opencms.org/taglib/cms" %><html><head><title><cms:property name="Title" /></title><meta HTTP-EQUIV="CONTENT-TYPE" CONTENT="text/html; CHARSET=<cms:property name="content-encoding" default="UTF-8" />" /></head><body><h2>測試網站的模板</h2><cms:include element= "body"/></body></html>
<%@ taglib prefix="cms" uri="http://www.opencms.org/taglib/cms" %><html><head><title><cms:property name="Title" /></title><meta HTTP-EQUIV="CONTENT-TYPE" CONTENT="text/html; CHARSET=<cms:property name="content-encoding" default="UTF-8" />" /></head><body><h2>測試網站的模板</h2><cms:include element= "body"/></body></html>六、創建項目,包含網站資源和模塊資源(項目的詳細介紹以后會單獨的文章,在此先不多說),如下圖:

七、用模板生成頁面,切換到testWebProj項目,再切換到“我的測試站點”,新建“頁面”,如下圖:

名稱輸入為“index.html”,也可輸入“index”系統會自動增加“.html”的后綴,模板選擇剛剛創建的“我的測試網站——模板一”

創建頁面后,編輯頁面,輸入內容

保存,瀏覽效果如下:

八、發布項目,如下圖,確定當前項目為“testWebProj”,單擊“發布項目”

發布完成后,切換到Online項目,站點選擇“我的測試站點”

點擊瀏覽index.html,結果如下圖:

]]>