#
ZSP project started.SourceView2.0 and SourceFlow1.0 will be
deployed there.
This project is my first project since I came to GZ,wishing it
success.
Fedora為什么不用mp3,而選擇ogg?
Freedom: Make ogg, not mp3
Why is mp3 popular? Because it's better than everything else out there?
No. mp3 is popular because its creators licensed it broadly to spur its adoption. Then, once it was the de facto format, they started to enforce their patents aggressively and restrictively.
The free and open multimedia codecs such as the Ogg family of codecs are superior, and they are not patent-encumbered. Never have been, never will be. That's why we support free and open formats like Ogg Vorbis (lossy) and FLAC (lossless) for general audio and Ogg Theora for video.
For those people who insist upon using mp3, it's not difficult to figure out how to get these players. Still, we'd much rather change the world instead of going along with it.
http://fedoraproject.org/wiki/Overview
An operating system, a set of projects, and a mindset.
What is Fedora? Fedora is a Linux-based operating system that showcases the latest in free and open source software. Fedora is always free for anyone to use, modify, and distribute. It is built by people across the globe who work together as a community: the Fedora Project. The Fedora Project is open and anyone is welcome to join. The Fedora Project is out front for you, leading the advancement of free, open software and content.
The operating system is Fedora. It comes out twice a year. It's completely free, and we're committed to keeping it that way. It's the best combination of robust and latest software that exists in the free software world.
The mindset is doing the right thing. To us, that means providing free and open software and content, at no cost, freely usable, modifiable, redistributable, and unencumbered by software patents.
覺得Fedora做得挺好,特別是對我們這樣的程序員。
集成了MySQL,Tomcat,JDK,Eclipse,C的編譯器以及C的庫文件,簡直是天然的開發環境。
今天用c連接mysql,調試成功。
編譯包含mysql的c程序的命令如下:
[root@localhost ~]# gcc -o /forc/testmy /forc/testmy.c -lz /usr/lib/mysql/libmysqlclient.so.15.0.0
同時,也試了一下Tomcat。
啟動tomcat使用如下命令:
cd /usr/share/tomcat5/bin
java -jar bootstrap.jar
停止tomcat:
java -jar bootstrap.jar stop
今天真正理解什么是“
Free software”
What is Free Software?
“Free software” is a matter of liberty, not price. To understand the concept, you should think of “free” as in “free speech”, not as in “free beer”.
Free software is a matter of the users' freedom to run, copy, distribute, study, change and improve the software. More precisely, it refers to four kinds of freedom, for the users of the software:
The freedom to run the program, for any purpose (freedom 0).
The freedom to study how the program works, and adapt it to your needs (freedom 1). Access to the source code is a precondition for this.
The freedom to redistribute copies so you can help your neighbor (freedom 2).
The freedom to improve the program, and release your improvements to the public, so that the whole community benefits (freedom 3). Access to the source code is a precondition for this.
大約有10年沒寫過c程序了。由于工作需要,我又重新開始學習c。
今天解決兩個問題:
1.段錯誤
原來字符串數組在使用前必須為它分配內存,這跟java可不一樣。用calloc就可以。
2.警告:隱式聲明與內建函數 ‘calloc’ 不兼容
加入#include "stdlib.h" 就可以了。
struct sockaddr {
unsigned short sa_family; /* address family, AF_xxx */
char sa_data[14]; /* 14 bytes of protocol address */
};
sa_family是地址家族,一般都是“AF_xxx”的形式。好像通常大多用的是都是AF_INET。
sa_data是14字節協議地址。
此數據結構用做bind、connect、recvfrom、sendto等函數的參數,指明地址信息。
但一般編程中并不直接針對此數據結構操作,而是使用另一個與sockaddr等價的數據結構
sockaddr_in(在netinet/in.h中定義):
struct sockaddr_in {
short int sin_family; /* Address family */
unsigned short int sin_port; /* Port number */
struct in_addr sin_addr; /* Internet address */
unsigned char sin_zero[8]; /* Same size as struct sockaddr */
};
struct in_addr {
unsigned long s_addr;
};
sin_family指代協議族,在socket編程中只能是AF_INET
sin_port存儲端口號(使用網絡字節順序)
sin_addr存儲IP地址,使用in_addr這個數據結構
sin_zero是為了讓sockaddr與sockaddr_in兩個數據結構保持大小相同而保留的空字節。
s_addr按照網絡字節順序存儲IP地址
sockaddr_in和sockaddr是并列的結構,指向sockaddr_in的結構體的指針也可以指向
sockadd的結構體,并代替它。也就是說,你可以使用sockaddr_in建立你所需要的信息,
在最后用進行類型轉換就可以了bzero((char*)&mysock,sizeof(mysock));//初始化
mysock結構體名
mysock.sa_family=AF_INET;
mysock.sin_addr.s_addr=inet_addr("192.168.0.1");
……
等到要做轉換的時候用:
(struct sockaddr*)mysock
---------send to--------
 #include "stdio.h"
#include "stdio.h"
#include "sys/socket.h"
#include "netinet/in.h"
int main(void)


 {
{
 struct sockaddr_in sockin;
struct sockaddr_in sockin;
int sockId = 0,ret = 0;
char* buf;
sockId = socket(AF_INET,SOCK_DGRAM,0);
if(sockId < 0)

 {
{
printf("Socket Failed!\n");
return 1;
 }
}
memset(&sockin,0x0,sizeof(sockin));
sockin.sin_family = AF_INET;
sockin.sin_port = htons(1234);
sockin.sin_addr.s_addr = inet_addr("192.168.2.4");
//memset(&buf,'A',100);
buf = "This is message from server";
ret = sendto(sockId,buf,100,0,(struct sockaddr *)&sockin,sizeof(sockin));
if(ret != 100)
{
printf("Sendto failed!\n");
return 1;
}
close(sockId);
printf("Sendto succeed!\n");
return 0;
 }
}
-----------receive----------
#include "stdio.h"
#include "sys/socket.h"
#include "netinet/in.h"
int main(void)
{
struct sockaddr_in sockin;
int sockId = 0,ret = 0;
char buf[100];
sockId = socket(AF_INET,SOCK_DGRAM,0);
if(sockId < 0)
{
printf("Socket Failed!\n");
return 1;
}
memset(&sockin,0x0,sizeof(sockin));
sockin.sin_family = AF_INET;
sockin.sin_port = htons(1234);
sockin.sin_addr.s_addr = INADDR_ANY;
ret = bind(sockId,(struct sockaddr *)&sockin,sizeof(sockin));
if(ret < 0)
{
printf("bind failed!\n");
return 1;
}
ret = recvfrom(sockId,buf,100,0,NULL,NULL);
if(ret < 0)
{
printf("Recvfrom failed!\n");
return 1;
}
printf("Recvfrom result=%d\n",ret);
close(sockId);
printf("%s\n",buf);
return 0;
}
http://www.knowsky.com/366521.html
在實際的任何一個系統中,查詢都是必不可少的一個功能,而查詢設計的好壞又影響到系統的響應時間和性能這兩個要害指標,尤其是當數據量變得越來越大時,于是如何處理大數據量的查詢成了每個系統架構設計時都必須面對的問題。本文將從數據及數據查詢的特點分析出發,結合討論現有各種解決方案的優缺點及其適用范圍,來闡述J2EE平臺下如何進行查詢框架的設計。
Value List Handler模式及其局限性
在J2EE應用中,對于大數據量查詢的處理有許多好的成功經驗,比如Value List Handler設計模式就是其中非常經典的一個,見圖1。該模式創建一個ValueListHandler對象來控制查詢的執行以及結果集的緩存,它通過DAO(Data Access Object)來執行查詢,并將數據庫返回的結果集(傳輸對象Transfer Object的集合)緩存起來,接下來的客戶端查詢請求將直接從緩存中獲得。它的特點主要體現在兩點:服務器端緩存數據,每次只返回客戶端本次操作所需的數據,通過這兩個措施來減少數據庫的訪問次數以及增加客戶端的響應速度,達到最優的查詢效果。當然,這里面隱含一個前提就是客戶端采用分頁的方式來瀏覽數據。關于該模式的具體介紹,請參考[Core J2EE Patterns]一書。
但是在實際的應用過程中,會發現該模式存在一定的局限性,其實可以說是該模式應用具有一些前提條件:
1、由于緩存是以內存來換性能,這對于小數據量會工作得很好,但是假如結果集很大,內存消耗將會非常嚴重。同時,消耗在處理結果集上的時間也會越來越長,比如要循環讀取記錄集中的數據,然后依次填充每個傳輸對象,想想看幾百萬條數據這樣處理起來肯定讓人不能忍受。過長的處理時間不僅降低反應速度,同時還會占用寶貴的數據庫連接資源,造成其它地方無連接可用。雖然,在DAO模式中利用CachedRowSet,Read Only RowSet ,RowSet Wrapper List等策略(詳見參考資料)來代替Transfer Object Collection策略,有效地提高了處理速度,但是仍然存在著在大集合數據中進行定位、遍歷等問題。試想一想,即使在CachedRowSet中的absolute(2000000)也是非常費時的操作。所有這一切的根源就在于緩存是一次性讀取所有的數據,雖然有時你可以利用業務邏輯來強制性增加一些限制條件(比如產品查詢必須選擇大類和次類),但這種限制往往是不牢靠的或者說只是一時的權宜之計。也有人提出,可以不必緩存所有的查詢結果,而采取只緩存部分結果集,比如500,1000條,但這樣一來,就涉及到復雜的查詢數據是否越界的控制,增加了復雜度,同時也不易實現。
2、既然使用緩存,那就不得不面對一個數據更新的問題,使用緩存,實際上就假定了在數據緩存期間,數據庫中的數據不會改變,或者這些改變可以不被反映出來。但是,在很多場合下(比如常見的業務系統中)這些數據庫中的數據經常會發生變化,而且這些改變需要及時反映給客戶端。
3、緩存其實存在一個基本前提,就是緩存的數據會被客戶端反復查詢使用,具體到分頁查詢就是客戶會選擇不同的頁數來查看數據。假如客戶端的查詢條件始終變化,或者用戶基本上只關心第一頁的數據(仔細琢磨一下用戶的習慣,這在很多中應用場合都很常見),那緩存就失去了應有的意義,變得多此一舉了。
數據分析
所以說,在決定是否應用某種設計模式前,我們需要對被查詢數據的特點以及這些數據以何種方式被使用(查詢的特點)進行一個分析,根據不同的結論來決定采用何種處理策略。而且,數據本身的特點和被使用的方式往往交織在一起,需要綜合起來考慮,但這其中主要的考量點還是數據查詢的特點。
一般來說,可以從以下幾個方面來分析數據:
1、 數據量大。
這是我們今天討論的數據的一個最基本特點,這個特點在查詢框架設計時要引起足夠的重視。
注重:大數據量的查詢是指查詢時匹配條件的數據量大,而不是指表中的數據量大,雖然大部分時候這兩者都是一致的。因為在某些情況下,業務邏輯可以限制或者只需要一次獲取很少量的數據,而查詢的表中的數據量卻可能很大,那這種情況就不屬于本文的討論范圍。
2、 關聯復雜,多表關聯。
越是簡單的數據可能關聯越少,而越是復雜的數據往往都是多表關聯,這樣很多時候你需要將這幾張表作為一個整體來考慮。
3、 變化頻率。
從這個角度出發,可以大致將數據分為以下幾類:幾乎不變化的睡眠數據;有規律定時更新的數據,比如招聘網站的職位信息;經常性無規律更新的數據。
4、 成長性。
數據是否具有成長性,要預見數據的成長性,并在現有方案中考慮這種成長性,避免到時候查詢框架的重新設計,象大部分的業務數據都具有這種成長性。
注重:這里也要非凡注重區分數據本身的成長性和數據查詢的成長性,這看似等同的兩者其實還是存在很大的區別。就拿招聘網站來說,有效職位的數據肯定是一天天在增加,具有高成長性,但是在某個區間(比如一個月,一個星期)內的有效職位查詢則變化不會太大,不具有成長性。而后者卻往往是實際系統中最常碰到的查詢情況。
5、 數據查詢的頻率和方式。
所有的數據查詢不可能被等同地使用,你要分清楚系統中的幾個要害查詢,這些查詢使用頻率高,響應要快。試想一想,假如一個電子商務系統的產品查詢每次都要讓顧客等上十秒鐘,結果就可想而知。
用戶的使用習慣分析
除了對數據查詢本身需要進行分析之外,我們還需要去分析一下用戶如何來使用或者看待這些數據,用戶的使用習慣如何。有人可能覺得這作用不大,或者很難去分析,其實查詢的最終使用者是用戶,他們的一些習慣會很大程度上左右你的設計。
1、 用戶關心數據哪些方面的特性,不關心哪些方面的特性。
上面我們分析了數據本身的許多特性,那用戶對其中哪些特性最敏感呢?比如說對臟數據非凡不能接受,那我們就必須在查詢框架設計時非凡照顧到這一點。因為再好的框架設計都不可能在每個方面都能達到最優的效果,當必須有所取舍的時候,我們就要明白哪些特性是客戶最關心的。
2、 用戶如何來使用數據。
現在一般查詢的客戶端都采用分頁的方式,一個查詢可能會存在十幾頁甚至幾十頁結果。對于某些查詢,用戶可能往往只關心第一頁或者前幾頁的結果,比如用戶需要查詢出最近完成的工單,而對于另外一些查詢,用戶可能對所有頁結果都很關注,比如用戶查詢出最近三天新增的招聘職位。這不同類型的查詢在查詢框架設計的時候都需要有所考慮并給予不同的處理策略。
查詢框架的設計
對數據及用戶使用習慣進行了仔細的分析,接下來就可以根據這些分析來設計你的查詢框架了。在J2EE架構下,對于大數據量的查詢主要采取以下兩種方法:
基于緩存的方式:
從數據庫得到全部(部分)數據,并將其在服務器端進行緩存,接下來的客戶端請求,將直接從緩存中取得需要的數據。這其實就是Value List Handler模式的原理,它主要適用于數據量不是非常大,變化不是很頻繁(或者變化頻繁但是有規律)且不具有成長性的情況,比如招聘網站或者電子商務網站的大部分查詢就非常適合采取這種方式。
采用這種方式,要非凡注重第一次查詢問題,避免響應性能達不到要求,因為每個查詢第一次都需要連接數據庫,從中獲取數據并緩存起來,所以第一次查詢會比接下來的查詢都顯得更慢一些。
對于數據的緩存,有以下幾種實現方式:
? 直接緩存在服務器端
Value List Handler模式就采取這種方式,并且可以根據不同的情況采取不同的緩存策略,比如Transfer Object集合,CachedRowSet等,這取決于你的DAO實現策略。
? 用臨時表來保存查詢結果
WLDJ(www.sys-con.com/weblogic/)雜志2004年第7期上有一篇名為“Handling Large Database Result Sets”的文章,它具體介紹了如何利用臨時表來改良Value List Handler模式以支持大型的J2EE應用。
當然除了以上這些方法以外,實現緩存也可以求助于操作系統的特定實現,以前我在IBM DW發表過一篇探討MMF在Java中應用的文章(見參考資料),可惜未有深入,有愛好的朋友可以參考一下。
在使用Value List Handler模式時,要非凡注重以下幾點:
1、 該模式一般和DAO模式搭配使用。
2、 該模式有POJO,stateful session bean兩種實現策略。
3、 假如采取stateful session bean實現策略,則默認該緩存的時間長度為整個用戶會話。
前面我們也提到過,假如數據不是絕對不變的,那緩存就面臨更新的問題,一旦更新就可能存在著數據不一致,假如恰巧客戶也希望能夠看到變化的效果,這個時候就需要采取某種措施來保證這種一致性。常見的措施可以是設置一個標志位,每次發生數據更新后都將其對應的標志位更新,查詢時假如發現標志位更新了,就直接從數據庫獲取數據,而不是從緩存中獲取數據。另外一種方式就是數據更新的同時主動去清空session中的緩存,假如采用stateful session bean實現策略的話。
當然,采取緩存方式的大數據量查詢一般來說都不大可能碰到設置更新標志位的問題,因為這種應用方式決定了數據不大可能變化,或者數據變化不要求馬上反應給用戶。比如招聘網站新增加了一些職位信息,假如這些更新恰巧發生在某些用戶的會話期間,且沒有設置更新標志位,那這些新增信息就不會反應到用戶的查詢結果中,這種處理方式也是可以接受的。
經過UI工程師的努力,我們的軟件變得更加美觀。
http://bbs.8s8s.com/linux/linux7571.htm
高速路由器的系統交換能力與處理能力是其有別于一般路由器能力的重要體現。目前,高速路由器的背板交換能力應達到40Gbps以上,同時系統即使暫時不提供OC-192/STM-64接口,也必須在將來無須對現有接口卡和通用部件升級的情況下支持該接口。在設備處理能力方面,當系統滿負荷運行時,所有接口應該能夠以線速處理短包,如40字節、64字節,同時,高速路由器的交換矩陣應該能夠無阻塞地以線速處理所有接口的交換,且與流量的類型無關。
指標之一: 吞吐量
吞吐量是路由器的包轉發能力。吞吐量與路由器端口數量、端口速率、數據包長度、數據包類型、路由計算模式(分布或集中)以及測試方法有關,一般泛指處理器處理數據包的能力。高速路由器的包轉發能力至少達到20Mpps以上。吞吐量主要包括兩個方面:
1. 整機吞吐量
整機指設備整機的包轉發能力,是設備性能的重要指標。路由器的工作在于根據IP包頭或者MPLS 標記選路,因此性能指標是指每秒轉發包的數量。整機吞吐量通常小于路由器所有端口吞吐量之和。
2. 端口吞吐量
端口吞吐量是指端口包轉發能力,它是路由器在某端口上的包轉發能力。通常采用兩個相同速率測試接口。一般測試接口可能與接口位置及關系相關,例如同一插卡上端口間測試的吞吐量可能與不同插卡上端口間吞吐量值不同。
指標之二:路由表能力
路由器通常依靠所建立及維護的路由表來決定包的轉發。路由表能力是指路由表內所容納路由表項數量的極限。由于在Internet上執行BGP協議的路由器通常擁有數十萬條路由表項,所以該項目也是路由器能力的重要體現。一般而言,高速路由器應該能夠支持至少25萬條路由,平均每個目的地址至少提供2條路徑,系統必須支持至少25個BGP對等以及至少50個IGP鄰居。
指標之三:背板能力
背板指輸入與輸出端口間的物理通路。背板能力是路由器的內部實現,傳統路由器采用共享背板,但是作為高性能路由器不可避免會遇到擁塞問題,其次也很難設計出高速的共享總線,所以現有高速路由器一般采用可交換式背板的設計。背板能力能夠體現在路由器吞吐量上,背板能力通常大于依據吞吐量和測試包長所計算的值。但是背板能力只能在設計中體現,一般無法測試。
指標之四:丟包率
丟包率是指路由器在穩定的持續負荷下,由于資源缺少而不能轉發的數據包在應該轉發的數據包中所占的比例。丟包率通常用作衡量路由器在超負荷工作時路由器的性能。丟包率與數據包長度以及包發送頻率相關,在一些環境下,可以加上路由抖動或大量路由后進行測試模擬。
指標之五:時延
時延是指數據包第一個比特進入路由器到最后一個比特從路由器輸出的時間間隔。該時間間隔是存儲轉發方式工作的路由器的處理時間。時延與數據包長度和鏈路速率都有關,通常在路由器端口吞吐量范圍內測試。時延對網絡性能影響較大, 作為高速路由器,在最差情況下, 要求對1518字節及以下的IP包時延均都小于1ms。
指標之六:背靠背幀數
背靠背幀數是指以最小幀間隔發送最多數據包不引起丟包時的數據包數量。該指標用于測試路由器緩存能力。具有線速全雙工轉發能力的路由器,該指標值無限大。
指標之七:時延抖動
時延抖動是指時延變化。數據業務對時延抖動不敏感,所以該指標通常不作為衡量高速路由器的重要指標。對IP上除數據外的其他業務,如語音、視頻業務,該指標才有測試的必要性。
指標之八:服務質量能力
1.隊列管理機制
隊列管理控制機制通常指路由器擁塞管理機制及其隊列調度算法。常見的方法有RED、WRED、 WRR、DRR、WFQ、WF2Q等。
排隊策略:
● 支持公平排隊算法。
● 支持加權公平排隊算法。該算法給每個隊列一個權(weight),由它決定該隊列可享用的鏈路帶寬。這樣,實時業務可以確實得到所要求的性能,非彈性業務流可以與普通(Best-effort)業務流相互隔離。
● 在輸入/輸出隊列的管理上,應采用虛擬輸出隊列的方法。
擁塞控制:
● 必須支持WFQ、RED等擁塞控制機制。
● 必須支持一種機制,由該機制可以為不符合其業務級別CIR/Burst合同的流量標記一個較高的丟棄優先級,該優先級應比滿足合同的流量和盡力而為的流量的丟棄優先級高。
● 在有可能存在輸出隊列爭搶的交換環境中,必須提供有效的方法消除頭部擁塞。
2.端口硬件隊列數
通常路由器所支持的優先級由端口硬件隊列來保證。每個隊列中的優先級由隊列調度算法控制。
指標之九:網絡管理
網管是指網絡管理員通過網絡管理程序對網絡上資源進行集中化管理的操作,包括配置管理、計賬管理、性能管理、差錯管理和安全管理。設備所支持的網管程度體現設備的可管理性與可維護性,通常使用SNMPv2協議進行管理。網管粒度指示路由器管理的精細程度,如管理到端口、到網段、到IP地址、到MAC地址等粒度。管理粒度可能會影響路由器轉發能力。
指標之十:可靠性和可用性
1.設備的冗余
冗余可以包括接口冗余、插卡冗余、電源冗余、系統板冗余、時鐘板冗余、設備冗余等。冗余用于保證設備的可靠性與可用性,冗余量的設計應當在設備可靠性要求與投資間折衷。 路由器可以通過VRRP等協議來保證路由器的冗余。
2.熱插拔組件
由于路由器通常要求24小時工作,所以更換部件不應影響路由器工作。部件熱插拔是路由器24小時工作的保障。
3.無故障工作時間
該指標按照統計方式指出設備無故障工作的時間。一般無法測試,可以通過主要器件的無故障工作時間計算或者大量相同設備的工作情況計算。
4.內部時鐘精度
擁有ATM端口做電路仿真或者POS口的路由器互連通常需要同步。在使用內部時鐘時,其精度會影響誤碼率。
在高速路由器技術規范中,高速路由器的可靠性與可靠性規定應達到以下要求:
① 系統應達到或超過99.999%的可用性。
② 無故障連續工作時間:MTBF>10萬小時。
③ 故障恢復時間:系統故障恢復時間 < 30 mins。
④ 系統應具有自動保護切換功能。主備用切換時間應小于50ms。
⑤ SDH和ATM接口應具有自動保護切換功能,切換時間應小于50ms。
⑥ 要求設備具有高可靠性和高穩定性。主處理器、主存儲器、交換矩陣、電源、總線仲裁器和管理接口等系統主要部件應具有熱備份冗余。線卡要求m+n備份并提供遠端測試診斷功能。電源故障能保持連接的有效性。
⑦ 系統必須不存在單故障點。
好幾年沒寫過存諸過程了,都忘光了。今天由于需求,又寫了一個。
create or replace procedure stat_app_traffic
as
queryhour varchar2(15);
lasthour number;
begin
lasthour:= to_number(to_char(sysdate,'HH24')) - 1;
if(lasthour=-1) then
queryhour:= to_char(sysdate-1,'YYYY-MM-DD ') || '23';
else
queryhour:= to_char(sysdate,'YYYY-MM-DD ') || lasthour;
end if;
insert into app_traffic(app,bytes,log_time)
select app,round(sum(bytes)/1024/1024,2),max(log_time) from
((select b.app,a.src_port port,a.out_bytes bytes,a.log_time
from raw_netflow a,app_config b
where a.src_port=b.port and a.protocol=b.protocol_id
and to_char(log_time,'YYYY-MM-DD HH24')=queryhour)
union
(select b.app,a.dst_port port,a.in_bytes bytes,a.log_time
from raw_netflow a,app_config b
where a.dst_port=b.port and a.protocol=b.protocol_id
and to_char(log_time,'YYYY-MM-DD HH24')=queryhour)) group by app;
commit;
end stat_app_traffic;
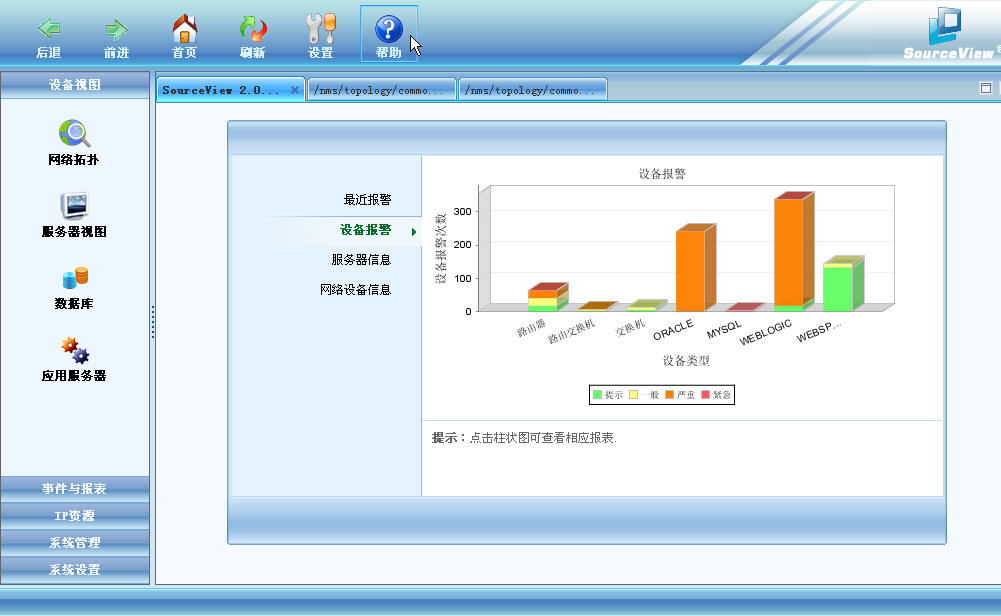
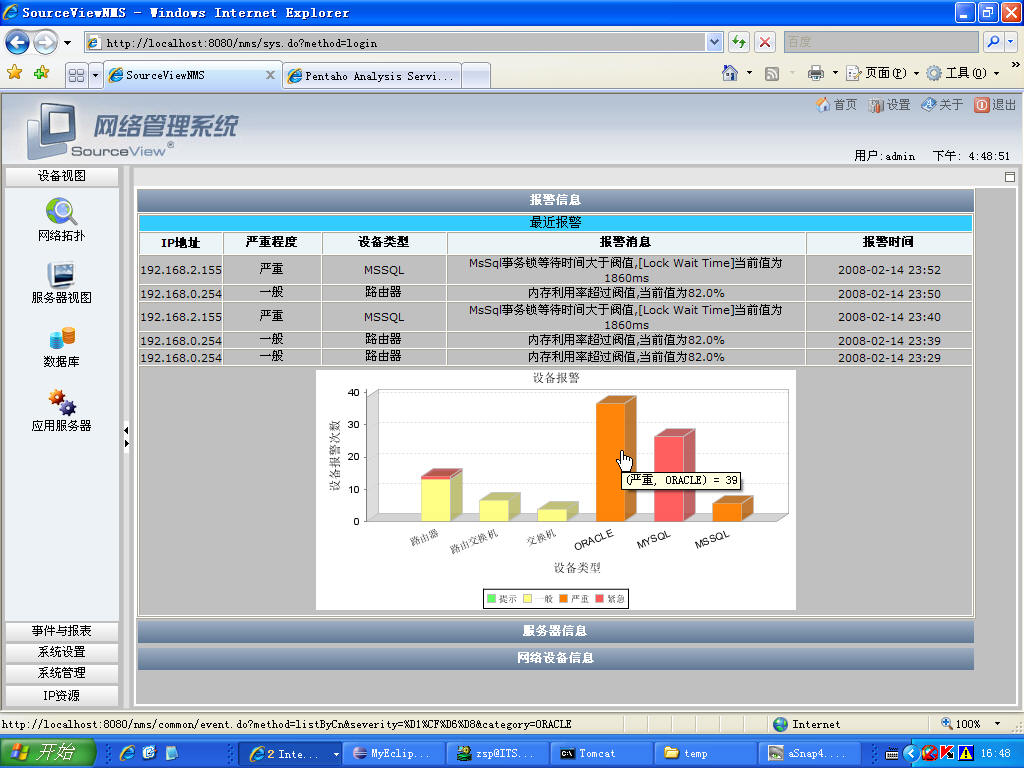
完成首頁,實現了JFreeChart柱狀圖可鉆取的功能。

讀后,終于對BI的一些基本概念有比較清楚地認識。