http://www.google.cn/search?complete=1&hl=zh-CN&newwindow=1&q=google&btnG=Google+%E6%90%9C%E7%B4%A2&meta=&aq=-1&oq=
complete
hl�Q�区�?br />
newwindow
q�Q�查询关键字
btnG
meta
aq
oq
http://www.google.cn/search?会蟩转到http://www.google.cn/webhp��面�Q?br />
http://www.google.cn/search?q=123���可以搜索,搞不懂;
]]>
HTTP URL (包含了用于查找某个资源的���_��的信�?的格式如下:
http://host[":"port][abs_path]
http表示要通过HTTP协议来定位网�l�资源;host表示合法的Internet��L��域名或者IP地址�Q�port指定一个端口号�Q��ؓ�I�则使用�~�省端口80�Q�abs_path指定��h��资源的URI�Q�如果URL中没有给出abs_path�Q�那么当它作�����求URI�Ӟ��必须�?#8220;/”的�Ş式给出,通常�q�个工作���览器自动帮我们完成�?br /> http://www.microsoft.com/china/index.htm。它的含义如下:
1.http://�Q�代表超文本传输协议�Q�通知microsoft.com服务器显�C�Web��,通常不用输入�Q?br /> 2.www�Q�代表一个Web(万维�|?服务器;
3.Microsoft.com/�Q�这是装有网��늚�服务器的域名�Q�或站点服务器的名称�Q?br /> 4.China/�Q��ؓ该服务器上的子目录,���好像我们的文�g夹;
5.Index.htm�Q�index.htm是文件夹中的一个HTML文�g(�|�页)�?br /> 三,HTTP 工作原理
HTTP协议是基于请�?响应范式�?相当于客��h��/服务�?。一个客��h��与服务器建立�q�接后,发送一个请求给服务器,��h��方式的格式�ؓ�Q�统一资源标识�W?URL)、协议版本号�Q�后�Ҏ��MIME信息包括��h��修饰�W�、客��h��信息和可能的内容。服务器接到��h��后,�l�予相应的响应信息,其格式�ؓ一个状态行�Q�包括信息的协议版本受���一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内宏V�?br /> 许多HTTP通讯是由一个用户代理初始化的�ƈ且包括一个申请在源服务器上资源的��h��。最���单的情况可能是在用户代理和服务器之间通过一个单独的�q�接来完成。在Internet上,HTTP通讯通常发生在TCP/IP�q�接之上。缺省端口是TCP80�Q�但其它的端口也是可用的。但�q��ƈ不预�C�着HTTP协议在Internet或其它网�l�的其它协协议之上才能完成。HTTP只预�C�着一个可靠的传输�?br /> �q�个�q�程���好像我们打电话订货一��P��我们可以打电话给商家�Q�告诉他我们需要什么规格的商品�Q�然后商家再告诉我们什么商品有货,什么商品缺货。这些,我们是通过电话�U�用电话联系(HTTP是通过TCP/IP)�Q�当然我们也可以通过传真�Q�只要商安���边也有传真�?br /> 四,HTTP ��h���Q�应�{�组�?br /> http://www.cnpaf.net/Class/HTTP/0532918532641885.html
]]>
一�Q�java中对字符的处�?br />
getBytes(charset)�Q�这是java字符串处理的一个标准函敎ͼ�其作用是���字�W�串所表示的字�W�按照charset�~�码�Q��ƈ以字节方式表�C�。注意字�W�串在java内存中��L��按unicode�~�码存储的。比�?中文"�Q�正常情况下�Q�即没有错误的时候)存储�?4e2d 6587"�Q�如果charset�?gbk"�Q�则被编码�ؓ"d6d0 cec4"�Q�然后返回字�?d6 d0 ce c4"。如果charset�?utf8"则最后是"e4 b8 ad e6 96 87"。如果是"iso8859-1"�Q�则�׃��无法�~�码�Q�最后返�?"3f 3f"�Q�两个问��P���?br />
new String(charset)�Q?/span>�q�是java字符串处理的另一个标准函敎ͼ�和上一个函数的作用相反�Q�将字节数组按照charset�~�码�q�行�l�合识别�Q�最后�{换�ؓunicode存储。参考上�q�getBytes的例子,"gbk" �?utf8"都可以得出正���的�l�果"4e2d 6587"�Q�但iso8859-1最后变成了"003f 003f"�Q�两个问��P���?/span>因�ؓutf8可以用来表示/�~�码所有字�W�,所以new String( str.getBytes( "utf8" ), "utf8" ) == str�Q�即完全可逆�?br />
setCharacterEncoding()�Q?/span>该函数用来设�|�http��h��或者相应的�~�码�?/span>对于request�Q�是指提交内容的�~�码�Q�指定后可以通过getParameter()则直接获得正���的字符�Ԍ��如果不指定,则默认��用iso8859-1�~�码�Q�需要进一步处理。参见下�q?表单输入"。值得注意的是在执行setCharacterEncoding()之前�Q�不能执行�Q何getParameter()。java doc上说明:This method must be called prior to reading request parameters or reading input using getReader()。而且�Q�该指定只对POST�Ҏ��有效�Q�对GET�Ҏ��无效。分析原因,应该是在执行�W�一个getParameter()的时候,java���会按照�~�码分析所有的提交内容�Q�而后�l�的getParameter()不再�q�行分析�Q�所以setCharacterEncoding()无效。而对于GET�Ҏ��提交表单是,提交的内容在URL中,一开始就已经按照�~�码分析所有的提交内容�Q�setCharacterEncoding()自然���无效�?/span>对于response�Q�则是指定输出内容的�~�码�Q�同�Ӟ��该设�|�会传递给���览器,告诉���览器输出内�Ҏ��采用的编码�?br />
二,web开发中字符�~�码几处讄���
对于web应用�E�序�Q�和�~�码有关的设�|�或者函数如下�?br />
jsp�~�译�Q?/span>指定文�g的存储编码,很明显,该设�|�应该置于文件的开头。例如:<@pagepageEncoding="GBK"%>。另外,对于一般class文�g�Q�可以在�~�译的时候指定编码�?br />
jsp输出�Q?/span>指定文�g输出到browser是��用的�~�码�Q�该讄���也应该置于文件的开头。例如:<%@ page contentType="text/html; charset= GBK" %>。该讄���和response.setCharacterEncoding("GBK")�{�效�?br />
meta讄����Q?/span>指定�|�页使用的编码,该设�|�对静态网��尤其有作用。因为静态网��|��法采用jsp的设�|�,而且也无法执行response.setCharacterEncoding()。例如:<META http-equiv="Content-Type" content="text/html; charset=GBK" />�Q?/span>如果同时采用了jsp输出和meta讄���两种�~�码指定方式�Q�则jsp指定的优先。因为jsp指定的直接体现在response中�?/span>需要注意的是,apache有一个设�|�可以给无编码指定的�|�页指定�~�码�Q�该指定�{�同于jsp的编码指定方式,所以会覆盖静态网��中的meta指定。所以有人徏议关闭该讄����?br />
form讄����Q?/span>当浏览器提交表单的时候,可以指定相应的编码。例如:<form accept-charset= "gb2312">。一般不必不使用该设�|�,���览器会直接使用�|�页的编码�?br />
三,URL地址
URL地址中含有中文字�W�是很麻烦的�Q�前面描�q�过使用GET�Ҏ��提交表单的情况,使用GET�Ҏ���Ӟ��参数���是包含在URL中�?br />
URL�~�码�Q�对于URL中的一些特�D�字�W�,���览器会自动�q�行�~�码。这些字�W�除�?/?&"�{�外�Q�还包括unicode字符�Q�比如汉子。这时的�~�码比较�Ҏ���?br />
IE有一个选项"��L��使用UTF-8发送URL"�Q�当该选项有效�Ӟ��IE���会对特�D�字�W�进行UTF-8�~�码�Q�同时进行URL�~�码。如果改选项无效�Q�则使用默认�~�码"GBK"�Q��ƈ且不�q�行URL�~�码。但是,对于URL后面的参敎ͼ�则��L��不进行编码,相当于UTF-8选项无效。比�?中文.html?a=中文"�Q�当UTF-8选项有效�Ӟ�����发送链�?%e4%b8%ad%e6%96%87.html?a=\x4e\x2d\x65\x87"�Q�而UTF-8选项无效�Ӟ�����发送链�?\x4e\x2d\x65\x87.html?a=\x4e\x2d\x65\x87"。注意后者前面的"中文"两个字只�?个字节,而前者却�?8个字节,�q�主要时URL�~�码的原因�?/span>当web server�Q�tomcat�Q�接收到该链接时�Q�将会进行URL解码�Q�即��L��"%"�Q�同时按照ISO8859-1�~�码�Q�上面已�l�描�q�ͼ�可以使用URLEncoding来设�|�成其它�~�码�Q�识别。上�q�C��子的�l�果分别�?\ue4\ub8\uad\ue6\u96\u87.html?a=\u4e\u2d\u65\u87"�?\u4e\u2d\u65\u87.html?a=\u4e\u2d\u65\u87"�Q�注意前者前面的"中文"两个字恢复成�?个字�W�。这里用"\u"�Q�表�C�是unicode�?/span>所以,�׃��客户端设�|�的不同�Q�相同的链接�Q�在服务器上得到了不同结果。这个问题不����h都遇刎ͼ�却没有很好的解决办法。所以有的网站会�����用户���试关闭UTF-8选项。不�q�,下面会描�q�C��个更好的处理办法�?br />
rewrite�Q?/span>熟悉的�h都知道,apache有一个功能强大的rewrite模块�Q�这里不描述其功能。需要说明的是该模块会自动将URL解码�Q�去�?�Q�,卛_��成上�q�web server�Q�tomcat�Q�的部分功能。有相关文档介绍说可以��用[NE]参数来关闭该功能�Q�但我试验�ƈ未成功,可能是因为版本(我��用的是apache 2.0.54�Q�问题。另外,当参��C��含有"?& "�{�符��L��时候,该功能将��D���pȝ��得不到正常结果�?/span>rewrite本��n��g��完全是采用字节处理的方式�Q�而不考虑字符串的�~�码�Q�所以不会带来编码问题�?br />
URLEncode.encode()�Q?/span>�q�是Java本��n提供对的URL�~�码函数�Q�完成的工作和上�q�UTF-8选项有效时浏览器所做的工作�怼�。值得说明的是�Q�java已经不赞成不指定�~�码来��用该�Ҏ���Q�deprecated�Q�。应该在使用的时候增加编码指定�?/span>当不指定�~�码的时候,该方法��用系�l�默认编码,�q�会��D��软�g�q�行�l�果得不���定。比如对�?中文"�Q�当�pȝ��默认�~�码�?gb2312"�Ӟ���l�果�?%4e%2d%65%87"�Q�而默认编码�ؓ"UTF-8"�Q�结果却�?%e4%b8%ad%e6%96%87"�Q�后�l�程序将难以处理。另外,�q�儿说的�pȝ��默认�~�码是由�q�行tomcat时的环境变量LC_ALL和LANG�{�决定的�Q�曾�l�出现过tomcat重启后就出现��q��的问题,最后才郁闷的发现是因�ؓ修改修改了这两个环境变量�?/span>������l�一指定�?UTF-8"�~�码�Q�可能需要修改相应的�E�序�?br />
一个解��x���?br />
上面说�v�q�,因�ؓ���览器设�|�的不同�Q�对于同一个链接,web server收到的是不同内容�Q�而��Y件系�l�有无法知道�q�中间的区别�Q�所以这一协议目前�q�存在缺陗��?br />
针对具体问题�Q�不应该侥幸认�ؓ所有客��L��IE讄���都是UTF-8有效的,也不应该�_�暴的徏议用户修改IE讄����Q�要知道�Q�用户不可能去记住每一个web server的设�|�。所以,接下来的解决办法���只能是让自��q���E�序多一�Ҏ��能:�Ҏ��内容来分析编码是否UTF-8�?nbsp;
比较�q�运的是UTF-8�~�码相当有规律,所以可以通过分析传输�q�来的链接内容,来判断是否是正确的UTF-8字符�Q�如果是�Q�则以UTF-8处理之,如果不是�Q�则使用客户默认�~�码�Q�比�?GBK"�Q�,下面是一个判断是否UTF-8的例子,如果你了解相应规律,���容易理�?/p>
int lLen=b.length,lCharCount=0;
for(int i=0;i<lLen && lCharCount<aMaxCount;++lCharCount){
byte lByte=b[i++];//to fast operation, ++ now, ready for the following for(;;)
if(lByte>=0) continue;//>=0 is normal ascii
if(lByte<(byte)0xc0 || lByte>(byte)0xf) return false;
int lCount=lByte>(byte)0xfc?5:lByte>(byte)0xf8?4
:lByte>(byte)0xf0?3:lByte>(byte)0xe0?2:1;
if(i+lCount>lLen) return false;
for(int j=0;j<lCount;++j,++i) if(b[i]>=(byte)0xc0) return false;
}
return true;
}
 public static String getUrlParam(String aStr,String aDefaultCharset)
public static String getUrlParam(String aStr,String aDefaultCharset)
 throws UnsupportedEncodingException{
throws UnsupportedEncodingException{
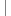
if(aStr==null) return null;
byte[] lBytes=aStr.getBytes("ISO-8859-1");
return new String(lBytes,StringUtil.isValidUtf8(lBytes)?"utf8":aDefaultCharset);
 }
}
没有包括对用户默认编码的识别�Q�这可以�Ҏ����h��信息的语�a�来判断,但不一定正���,因�ؓ我们有时候也会输入一些韩文,或者其他文字�?br />
可能会错误判断UTF-8字符�Q�一个例子是"学习"两个字,其GBK�~�码�? \xd1\xa7\xcf\xb0"�Q�如果��用上�q�isValidUtf8�Ҏ��判断�Q�将�q�回true。可以考虑使用更严格的判断�Ҏ���Q�不�q�估计效果不大�?br />
有一个例子可以证明google也遇��C��上述问题�Q�而且也采用了和上�q�相似的处理�Ҏ���Q�比如,如果在地址栏中输入"http://www.google.com/search?hl=zh-CN&newwindow=1&q=学习"�Q�google���无法正���识别,而其他汉字一般能够正常识别�?/span>最后,应该补充说明一下,如果不��用rewrite规则�Q�或者通过表单提交数据�Q�其实�ƈ不一定会遇到上述问题�Q�因�����时可以在提交数据时指定希望的�~�码。另外,中文文�g名确实会带来问题�Q�应该�}慎��用�?br />
四,�q���o�?/span>
如果需要统一讄����~�码�Q�则通过filter�q�行讄���是个不错的选择。在filter class中,可以�l�一为需要的��h��或者回应设�|�编码。参加上�q�setCharacterEncoding()。这个类apache已经�l�出了可以直接��用的例SetCharacterEncodingFilter�?/span>


]]>