Java LinkedHashMap和HashMap有什么區別和聯系?為什么LinkedHashMap會有著更快的迭代速度?LinkedHashSet跟LinkedHashMap有著怎樣的內在聯系?本文從數據結構和算法層面,結合生動圖解為讀者一一解答。
本文github地址
總體介紹
如果你已看過前面關于HashSet和HashMap,以及TreeSet和TreeMap的講解,一定能夠想到本文將要講解的LinkedHashSet和LinkedHashMap其實也是一回事。LinkedHashSet和LinkedHashMap在Java里也有著相同的實現,前者僅僅是對后者做了一層包裝,也就是說LinkedHashSet里面有一個LinkedHashMap(適配器模式)。因此本文將重點分析LinkedHashMap。
LinkedHashMap實現了Map接口,即允許放入key為null的元素,也允許插入value為null的元素。從名字上可以看出該容器是linked list和HashMap的混合體,也就是說它同時滿足HashMap和linked list的某些特性。可將LinkedHashMap看作采用linked list增強的HashMap。
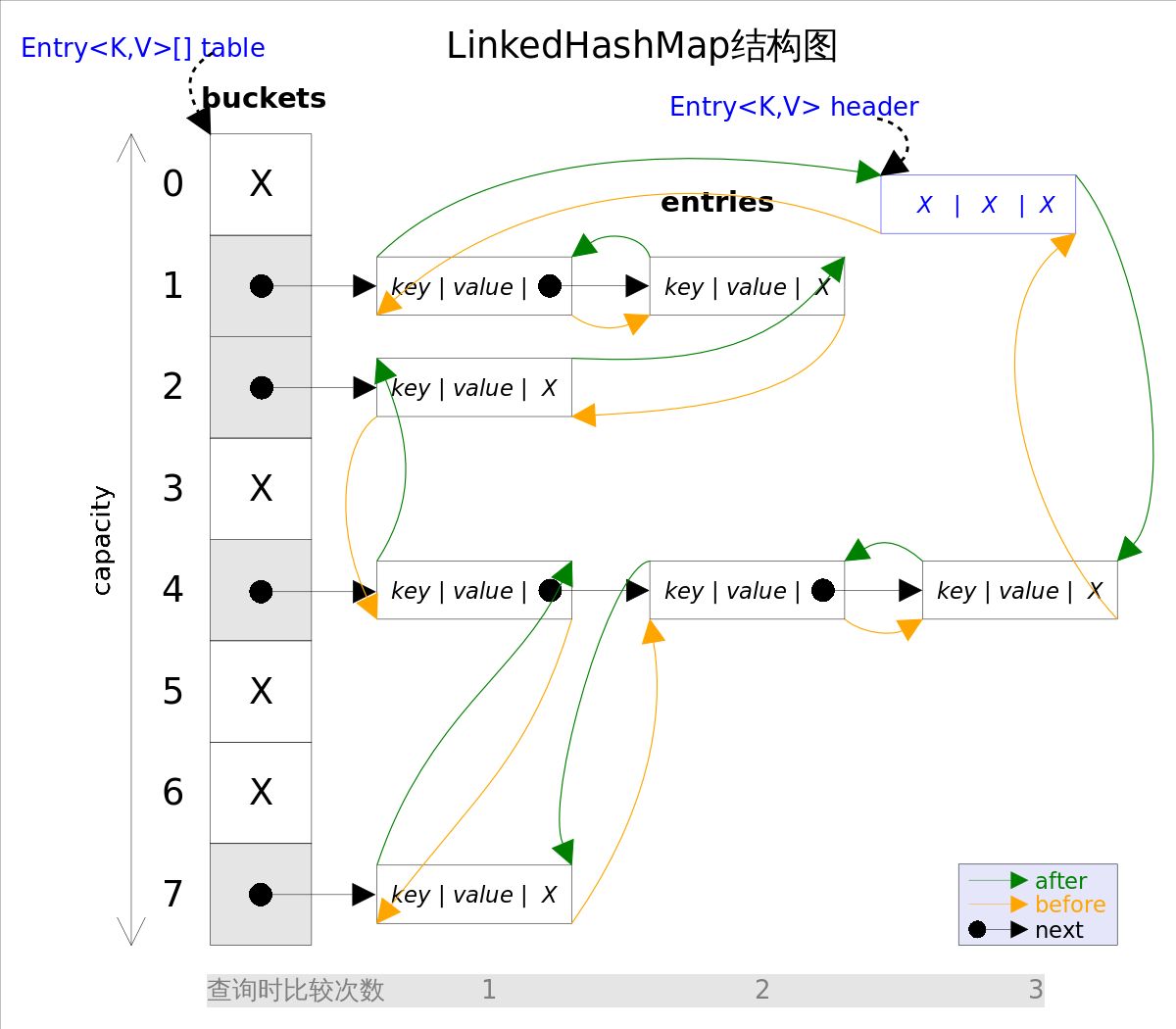
事實上LinkedHashMap是HashMap的直接子類,二者唯一的區別是LinkedHashMap在HashMap的基礎上,采用雙向鏈表(doubly-linked list)的形式將所有entry連接起來,這樣是為保證元素的迭代順序跟插入順序相同。上圖給出了LinkedHashMap的結構圖,主體部分跟HashMap完全一樣,多了header指向雙向鏈表的頭部(是一個啞元),該雙向鏈表的迭代順序就是entry的插入順序。
除了可以保迭代歷順序,這種結構還有一個好處:迭代LinkedHashMap時不需要像HashMap那樣遍歷整個table,而只需要直接遍歷header指向的雙向鏈表即可,也就是說LinkedHashMap的迭代時間就只跟entry的個數相關,而跟table的大小無關。
有兩個參數可以影響LinkedHashMap的性能:初始容量(inital capacity)和負載系數(load factor)。初始容量指定了初始table的大小,負載系數用來指定自動擴容的臨界值。當entry的數量超過capacity*load_factor時,容器將自動擴容并重新哈希。對于插入元素較多的場景,將初始容量設大可以減少重新哈希的次數。
將對象放入到LinkedHashMap或LinkedHashSet中時,有兩個方法需要特別關心:hashCode()和equals()。hashCode()方法決定了對象會被放到哪個bucket里,當多個對象的哈希值沖突時,equals()方法決定了這些對象是否是“同一個對象”。所以,如果要將自定義的對象放入到LinkedHashMap或LinkedHashSet中,需要*@Override*hashCode()和equals()方法。
通過如下方式可以得到一個跟源Map迭代順序一樣的LinkedHashMap:
void foo(Map m) {
Map copy =
new LinkedHashMap(m);

}
出于性能原因,LinkedHashMap是非同步的(not synchronized),如果需要在多線程環境使用,需要程序員手動同步;或者通過如下方式將LinkedHashMap包裝成(wrapped)同步的:
Map m = Collections.synchronizedMap(new LinkedHashMap(...));
方法剖析
get()
get(Object key)方法根據指定的key值返回對應的value。該方法跟HashMap.get()方法的流程幾乎完全一樣,讀者可自行參考前文,這里不再贅述。
put()
put(K key, V value)方法是將指定的key, value對添加到map里。該方法首先會對map做一次查找,看是否包含該元組,如果已經包含則直接返回,查找過程類似于get()方法;如果沒有找到,則會通過addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry。
注意,這里的插入有兩重含義:
- 從
table的角度看,新的entry需要插入到對應的bucket里,當有哈希沖突時,采用頭插法將新的entry插入到沖突鏈表的頭部。 - 從
header的角度看,新的entry需要插入到雙向鏈表的尾部。
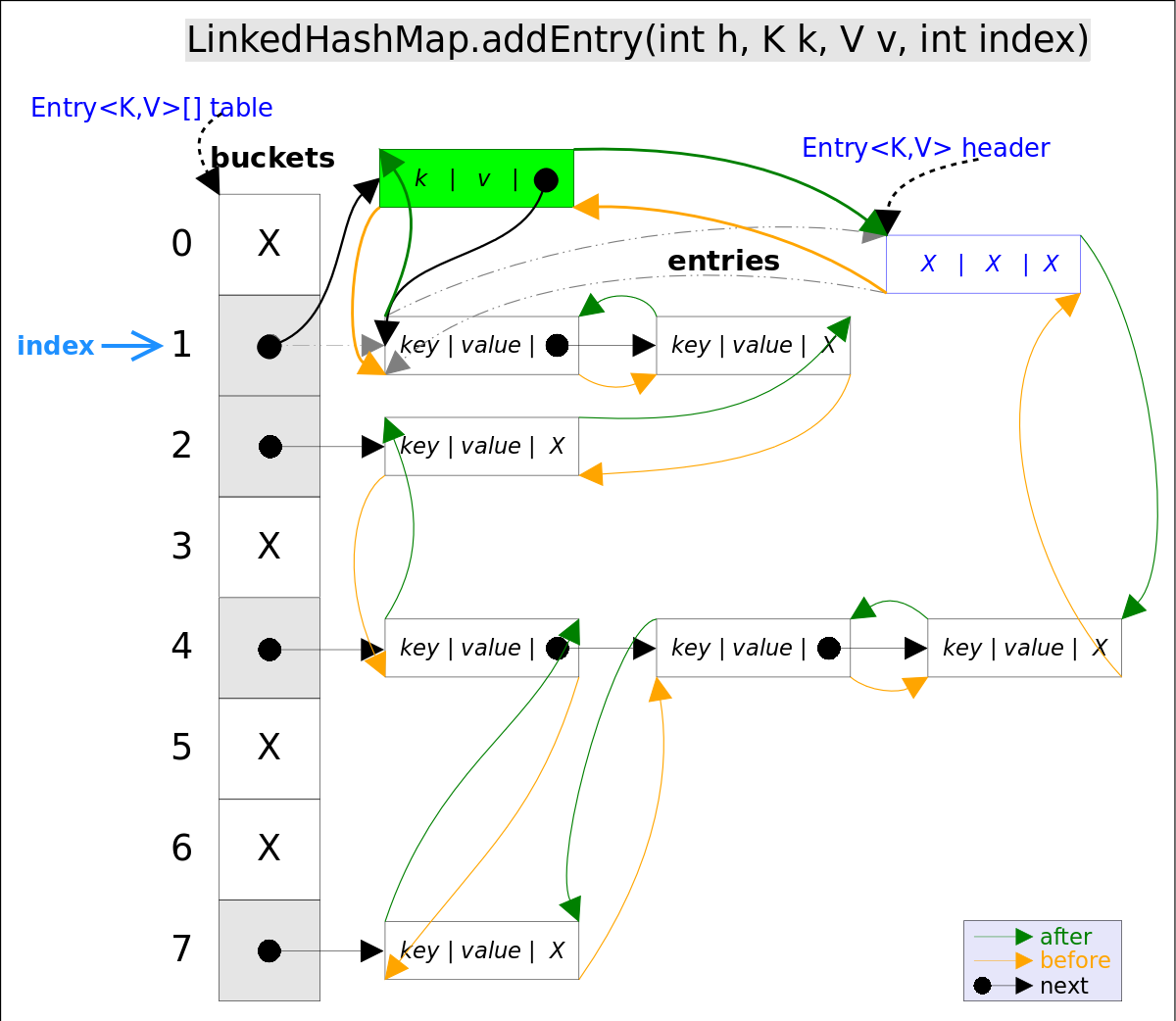
addEntry()代碼如下:
// LinkedHashMap.addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 自動擴容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);// hash%table.length
}
// 1.在沖突鏈表頭部插入新的entry
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 2.在雙向鏈表的尾部插入新的entry
e.addBefore(header);
size++;
}
上述代碼中用到了addBefore()方法將新entry e插入到雙向鏈表頭引用header的前面,這樣e就成為雙向鏈表中的最后一個元素。addBefore()的代碼如下:
// LinkedHashMap.Entry.addBefor(),將this插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
上述代碼只是簡單修改相關entry的引用而已。
remove()
remove(Object key)的作用是刪除key值對應的entry,該方法的具體邏輯是在removeEntryForKey(Object key)里實現的。removeEntryForKey()方法會首先找到key值對應的entry,然后刪除該entry(修改鏈表的相應引用)。查找過程跟get()方法類似。
注意,這里的刪除也有兩重含義:
- 從
table的角度看,需要將該entry從對應的bucket里刪除,如果對應的沖突鏈表不空,需要修改沖突鏈表的相應引用。 - 從
header的角度來看,需要將該entry從雙向鏈表中刪除,同時修改鏈表中前面以及后面元素的相應引用。
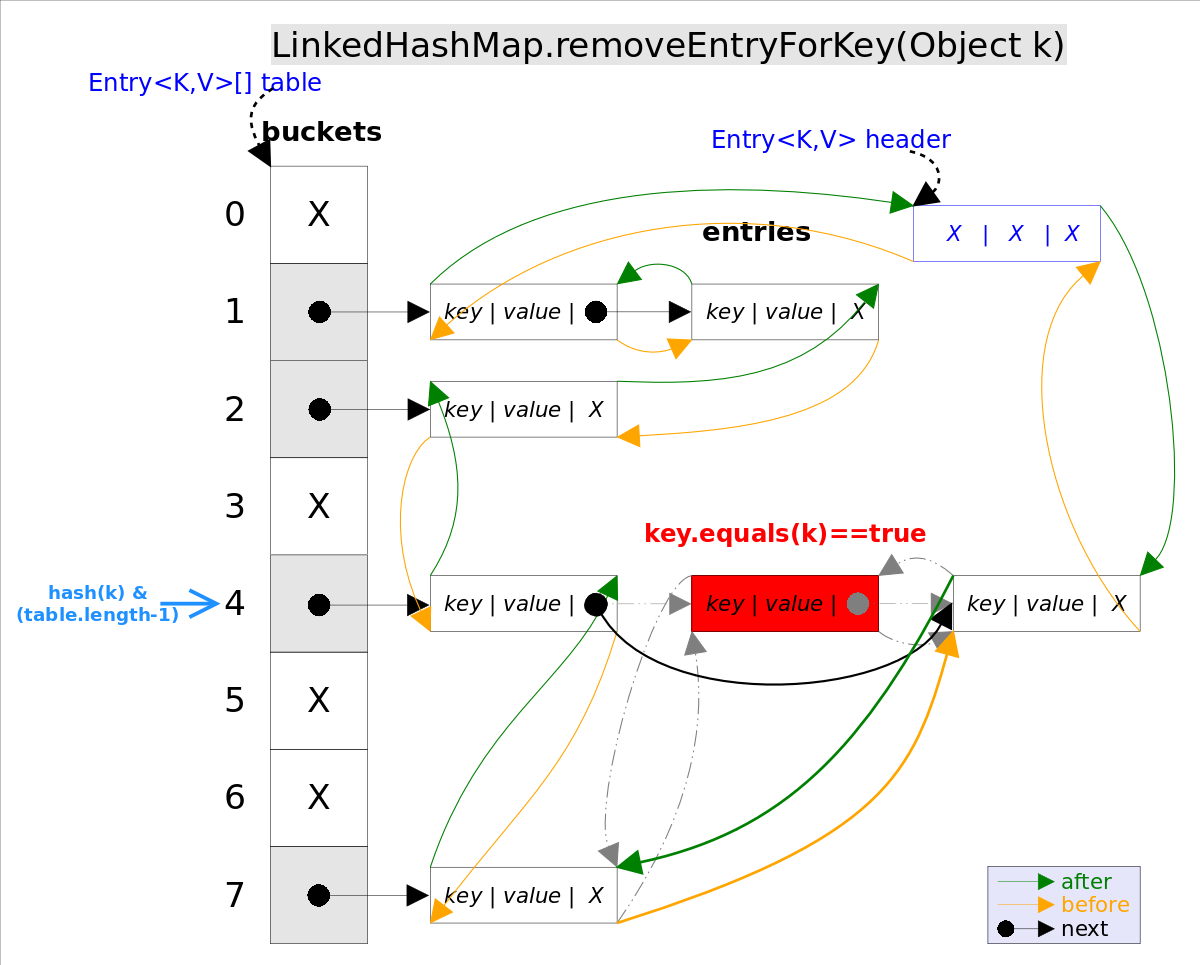
removeEntryForKey()對應的代碼如下:
// LinkedHashMap.removeEntryForKey(),刪除key值對應的entry
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key ==
null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
// hash&(table.length-1)
Entry<K,V> prev = table[i];
// 得到沖突鏈表
Entry<K,V> e = prev;
while (e !=
null) {
// 遍歷沖突鏈表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key !=
null && key.equals(k)))) {
// 找到要刪除的entry
modCount++; size--;
// 1. 將e從對應bucket的沖突鏈表中刪除
if (prev == e) table[i] = next;
else prev.next = next;
// 2. 將e從雙向鏈表中刪除
e.before.after = e.after;
e.after.before = e.before;
return e;
}
prev = e; e = next;
}
return e;
}
LinkedHashSet
前面已經說過LinkedHashSet是對LinkedHashMap的簡單包裝,對LinkedHashSet的函數調用都會轉換成合適的LinkedHashMap方法,因此LinkedHashSet的實現非常簡單,這里不再贅述。
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
// LinkedHashSet里面有一個LinkedHashMap
public LinkedHashSet(
int initialCapacity,
float loadFactor) {
map =
new LinkedHashMap<>(initialCapacity, loadFactor);
}
public boolean add(E e) {
//簡單的方法轉換
return map.put(e, PRESENT)==
null;
}
}