Hadoop包含两个部分�Q?/span>
1、HDFS
即Hadoop Distributed File System (Hadoop分布式文件系�l?
HDFS ��h��高容错性,�q�且可以被部�|�在低�h的硬件设备之上。HDFS很适合那些有大数据集的应用�Q��ƈ且提供了�Ҏ��据读写的高吞吐率。HDFS是一�?master/slave的结构,���通常的部�|�来��_��在master上只�q�行一个Namenode�Q�而在每一个slave上运行一个Datanode�?br /> HDFS 支持传统的层�ơ文件组�l�结构,同现有的一些文件系�l�在操作上很�c�M���Q�比如你可以创徏和删除一个文�Ӟ��把一个文件从一个目录移到另一个目录,重命名等�{�操 作。Namenode���理着整个分布式文件系�l�,�Ҏ��件系�l�的操作�Q�如建立、删除文件和文�g夹)都是通过Namenode来控制�?nbsp;
下面是HDFS的结构:
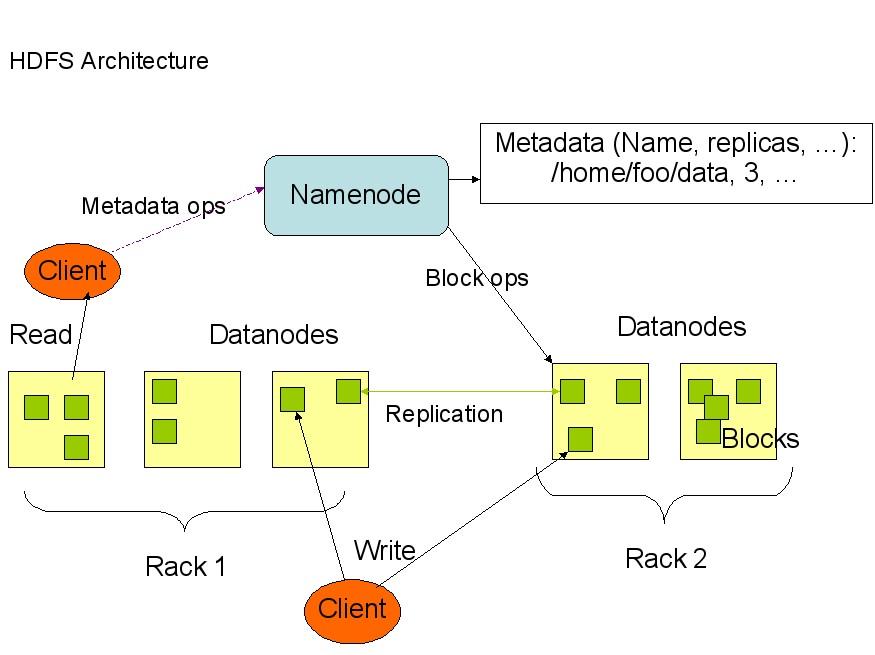
从上面的图中可以�?出,Namenode�Q�Datanode�Q�Client之间的通信都是建立在TCP/IP的基���之上的。当Client要执行一个写入的操作的时候,命��o 不是马上���发送到Namenode�Q�Client首先在本��Z��临时文�g夹中�~�存�q�些数据�Q�当临时文�g夹中的数据块辑ֈ�了设定的Block的��|��默认�?64M�Q�时�Q�Client便会通知Namenode�Q�Namenode便响应Client的RPC��h���Q�将文�g名插入文件系�l�层�ơ中�q�且�?Datanode中找��C��块存放该数据的block�Q�同时将该Datanode及对应的数据块信息告诉Client�Q�Client便这些本��C��时文件夹�?的数据块写入指定的数据节炏V�?br /> HDFS采取了副本策略,其目的是��Z��提高�pȝ��的可靠性,可用性。HDFS的副本放�|�策略是三个副本�Q?一个放在本节点上,一个放在同一机架中的另一个节点上�Q�还有一个副本放在另一个不同的机架中的一个节点上。当前版本的hadoop0.12.0中还没有�?玎ͼ�但是正在�q�行中,�怿�不久���可以出来了�?br />
2、MapReduce的实�?br />
MapReduce是Google 的一��w��要技术,它是一个编�E�模型,用以�q�行大数据量的计���。对于大数据量的计算�Q�通常采用的处理手法就是�ƈ行计���。至���现阶段而言�Q�对许多开发�h员来 ��_���q�行计算�q�是一个比较遥�q�的东西。MapReduce���是一�U�简化�ƈ行计���的�~�程模型�Q�它让那些没有多����ƈ行计���经验的开发�h员也可以开发�ƈ行应用�?br /> MapReduce的名字源于这个模型中的两��Ҏ��心操作:Map�?Reduce。也许熟悉Functional Programming�Q?/span>函数式编�E?/span>�Q?的�h见到�q�两个词会倍感亲切。简单的说来�Q�Map是把一�l�数据一对一的映����ؓ另外的一�l�数据,其映���的规则�׃��个函数来指定�Q�比如对[1, 2, 3, 4]�q�行�?的映���就变成了[2, 4, 6, 8]。Reduce是对一�l�数据进行归�U�,�q�个归约的规则由一个函数指定,比如对[1, 2, 3, 4]�q�行求和的归�U�得到结果是10�Q�而对它进行求�U�的归约�l�果�?4�?br />
关于MapReduce的内容,�����看看孟岩的这��?/span>MapReduce:The Free Lunch Is Not Over! �q�篇���是介绍的比较详�l�的。MapReduce的算法内容见Google文档�Q?a title="MapReduce.pdf" >MapReduce.pdf
有关其它介绍Hadoop的文章徏议看下:分布式计���开源框架Hadoop介绍 。(what�Q�why�Q�how提的不错�Q?br />
安装配置可以看:1�?a rel="permalink">Hadoop中的集群配置和��用技�?/a>
2�?a >Hadoop应用之Hadoop安装��?/a>
3�?a title="Hadoop安装部��v指南" >Hadoop安装部��v指南
如果要开发的话,初步参考:Hadoop基本���程与应用开�?/a>
其中用到数据库的部分�Q�在Hadoop�?.19.0开始支撑数据库讉K���Q�主要采用DBInputFormat来访问数据库。文章可见:Hadoop中的数据库访�?/a>
]]>